Lowest TCO for
Spark, guaranteed!
Open Source, Databricks,
Azure Synapse, Spark RAPIDs
WHY Zettabolt
We understand Spark inside-out. Whether it is profiling Spark for performance or whether it is optimizing its workloads to maximize cost-savings and improving performance, we have done it all many a times. We have mastered the profile-optimize loop of Spark:
PROFILE
OPTIMIZE
SPARK
PROFILING
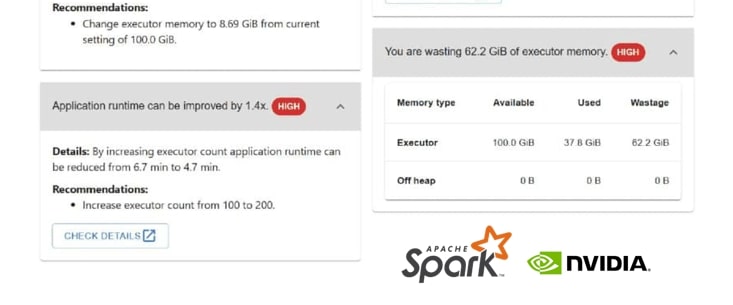
Besides deep understanding of profilers available with various Spark distros, we deploy our own powerful super-profiler ZettaProf to extract last bit of performance and cost-savings for customer’s workloads
ZettaProf is extensible to accommodate bespoke profiling requirements for specific use cases.

SPARK
OPTIMIZATION
Spark distros expertise:
-
Open Source, Databricks, Azure Synapse, RAPIDs, EMR
Optimizations applied:
-
Resource sizing : CPUs, RAM, disk, network, parallelism
Right machines : Best suited machines on AWS, Azure, GCP etc.
Query rewrites
Table scan : partitioning, bucketing, skew handling, serialization, S3 slowness
Query : JOIN optimizations, shuffle minimization, caching etc.

SPARK IN
DATA PROCESSING FLOW
End-to-end pipelines for:
ETL, BI, AI/ML
Reading data from any source (DBs, devices etc.) and connecting to analytic tools (Looker, Tableau etc.)
Benchmarking:
Comparing performance across various distros, machine configurations, cloud options
Against other data processing options (Hive, Presto etc.)

CUSTOMER CASE STUDIES
OUR BLOGS & WHITEPAPERS