CPU: Can The Traditional Work-Horse Continue To Gallop?

Introduction
CPU has been main work-horse for computation for past five decades! Adherence to Moore’s law has ensured that CPUs continued to improve to keep up with demands for computing. In this blog we will cover how programs run on CPUs. Why CPUs are preferred choices for running Big Data workloads? What are scale up/out techniques to improve the performance of any system? With Moore’s law hitting a wall, are CPUs alone sufficient to meet the demands of modern computing?
Running a program on CPU
In most traditional x86 based processors, programs are compiled into instructions which are then executed in a sequential manner. Figure below shows one simple program being run as a set of instructions.
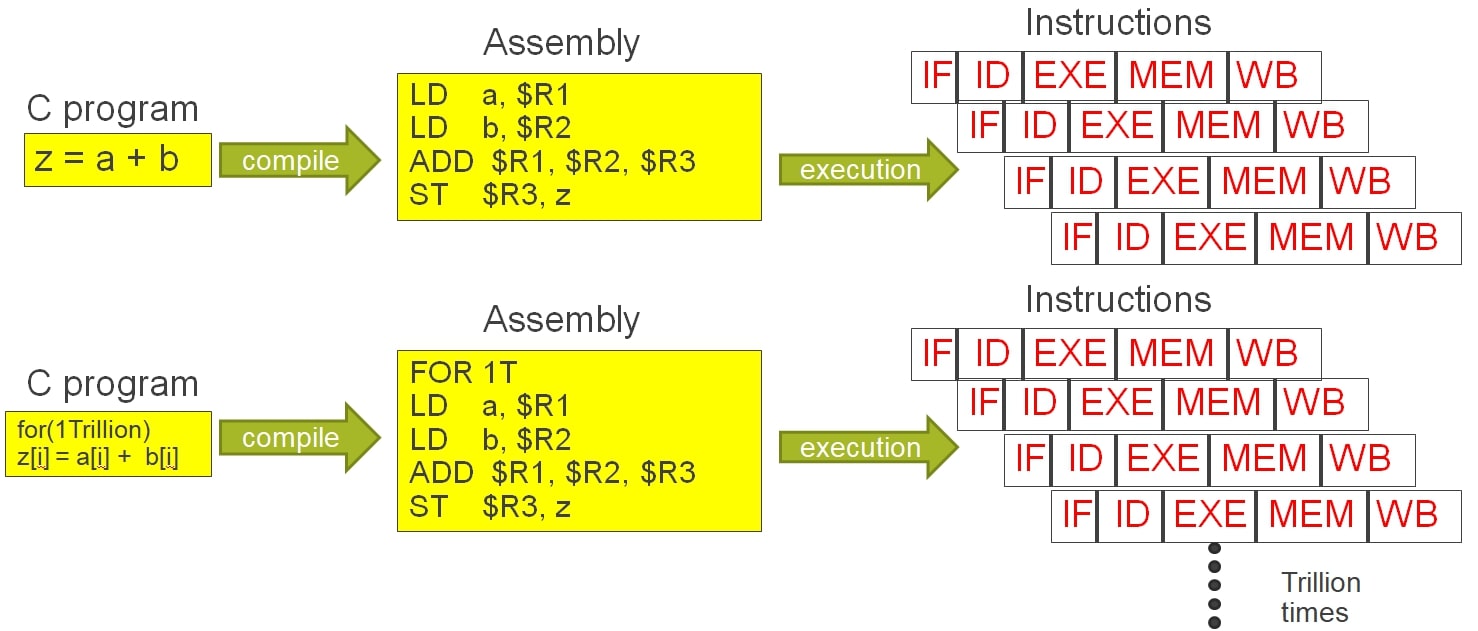
In most traditional processor designs, the EXE stage is where the main computation or operation occurs, and it often utilizes ALU or FPU. This stage needs to be executed sequentially because subsequent instructions may depend on the result of the current instruction.
However, pipelining can be applied to other stages such as IF, ID, MEM, and WB. This means that while one instruction is being executed in the EXE stage, the subsequent instructions can enter and progress through other stages of the pipeline. This overlap improves throughput and allows for more efficient use of the processor resources.
It's important to note that pipelining introduces challenges such as data hazards, control hazards, and structural hazards, which need to be addressed to ensure correct operation and performance of the processor
CPU for Big Data
Handling petabytes of data efficiently requires addressing the three Vs of Big Data: Volume, Velocity and Variety. Here are some strategies to get results from petabytes of data as fast as possible:
Distributed Computing: Utilize distributed computing frameworks like Apache Hadoop or Apache Spark to process data in parallel across multiple nodes. This allows for horizontal scalability, enabling processing of large volumes of data in a distributed manner.
Data Partitioning: Partition data into smaller chunks that can be processed independently. By distributing data across multiple nodes and processing them in parallel, you can achieve faster processing times.
Parallel Processing: Use parallel processing techniques within distributed computing frameworks to perform computations simultaneously on multiple partitions of data. This includes parallelizing tasks such as map-reduce operations in Hadoop or leveraging Spark's RDDs (Resilient Distributed Datasets) for parallel processing.
In-Memory Processing: Utilize in-memory processing frameworks like Apache Spark to minimize disk I/O overhead and speed up data processing. By keeping data in memory across multiple stages of computation, you can reduce latency and achieve faster results.
Data Compression and Serialization: Compress data to reduce storage requirements and minimize data transfer overhead. Additionally, use efficient serialization formats like Apache Avro or Apache Parquet to optimize data storage and processing efficiency.
Data Indexing and Caching: Implement data indexing and caching mechanisms to accelerate data retrieval and processing. By pre-computing and caching intermediate results, you can avoid redundant computations and improve overall processing speed.
Optimized Data Storage: Choose appropriate data storage solutions tailored to your specific use case. This may include distributed file systems like Hadoop Distributed File System (HDFS), columnar databases, NoSQL databases, or cloud-based storage solutions optimized for Big Data processing.
Data Pipelining and Streaming: Implement data pipelining and streaming architectures to process data in real-time or near real-time. By continuously processing incoming data streams and leveraging stream processing frameworks like Apache Kafka or Apache Flink, you can obtain results faster compared to batch processing approaches.
Optimized Algorithms and Data Structures: Use optimized algorithms and data structures tailored to your specific data processing tasks. This includes leveraging algorithms designed for parallel processing and choosing data structures that minimize computational complexity and memory overhead.
By combining these strategies and leveraging advanced technologies and frameworks, you can efficiently process petabytes of data and obtain results as fast as possible in the Big Data domain.
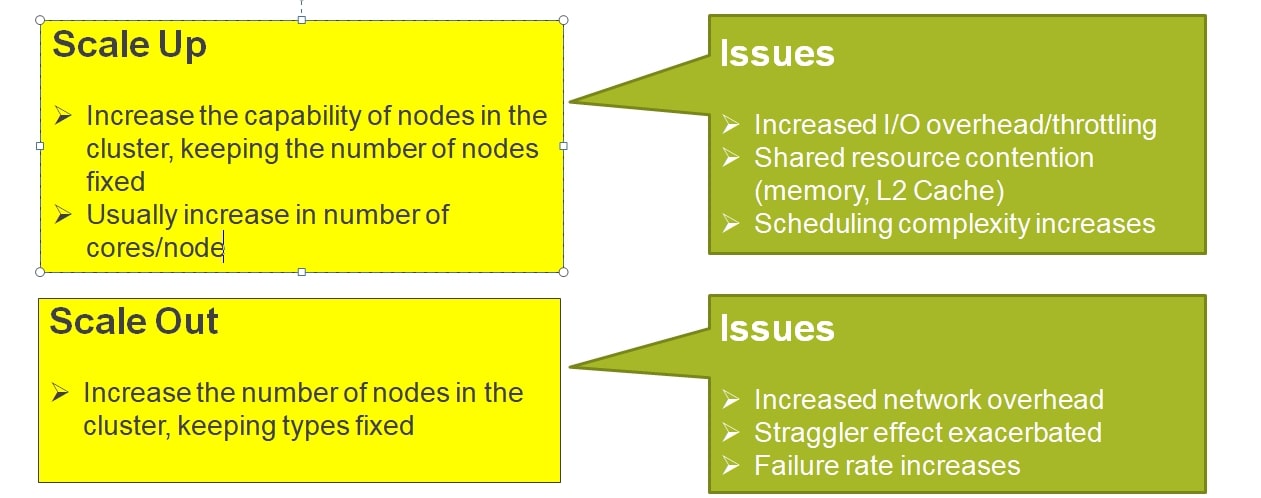
Scale-up and scale-out techniques are very widely used in distributed computing. Figure below shows what they are and issues associated with using them.
CPU has hit a performance wall
Even though CPUs have continuosuly improved on speed and by utilizing multi-core etc. techniques, their speed and performance have started to saturate.
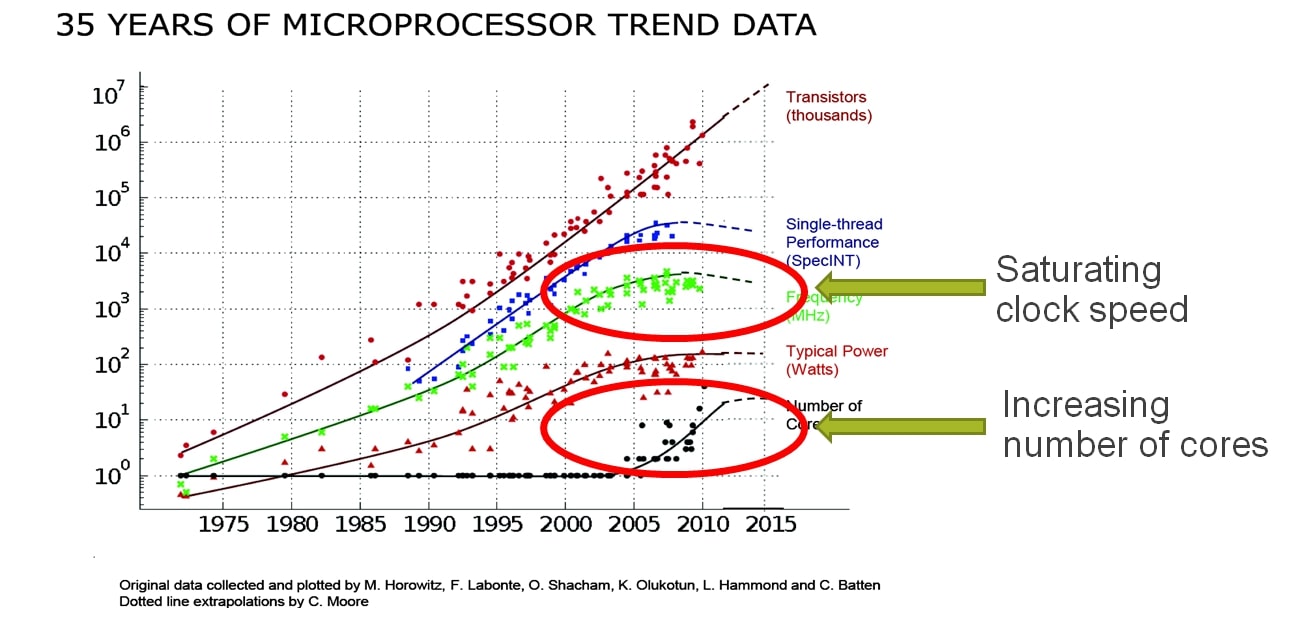
The saturation of CPU speed can be attributed to several factors, but two main reasons are:
Limits in Semiconductor Process Improvement: Moore's Law, which predicted a doubling of the number of transistors on a chip approximately every two years, has encountered significant challenges as semiconductor processes approach physical limits. As the size of transistors decreases, they reach a point where quantum effects and other physical limitations make further miniaturization difficult. This has led to the slowing down of traditional CPU speed improvements as semiconductor processes stagnate around 10 nanometers and below.
Power Dissipation Constraints: As CPUs became faster and more powerful, they also started consuming more power. However, power dissipation is reaching critical levels, with modern CPUs already touching or exceeding 1000 watts under peak loads. This poses significant challenges in terms of cooling solutions, energy efficiency, and overall system design. As a result, there's a diminishing return on increasing CPU speed due to the practical limitations imposed by power dissipation.
These two factors combined have contributed to the saturation of CPU speed, leading to a shift in focus towards other aspects of computing performance such as parallelism, multi-core architectures, and optimization of existing hardware resources rather than solely relying on increasing clock speeds.
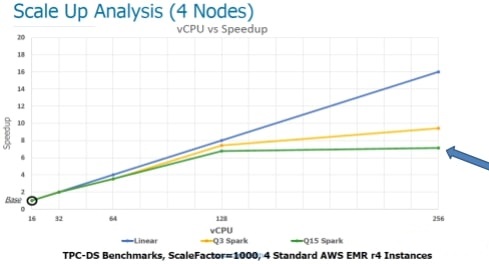
Using more CPU cores is not the solution
As the figure shows, simply increasing number of cores is not going to improve the performance. Cost goes up linearly but not the speed!
Computation industry realizes the limitations that CPUs are running into. Huge effort is being put into to make GPUs and FPGAs part of more and more compute heavy workloads. Quantum computing is new kid on the block but has few decades of catching up to do before it can be deployed at commercial scale.