Architecture To Boost Spark's Performance

Spark's performance has been under a lot of pressure of late, largely due to its explosive growth in recent years. Any performance improvement translates to substantial cost savings.
Here are some strategies for speeding Spark SQL queries:
- Predicate Pushdown
- Columnar Storage
- Partitioning
- Caching and Data Replication
- Hardware Acceleration
- Optimization Configurations
By exploring these techniques and features within Spark SQL, user can accelerate query performance, improve data processing efficiency, and unlock the full potential of Spark-based analytics workflows.
Big Data Query Processing
Big data query processing involves analyzing and extracting insights from large volumes of data using distributed computing frameworks and specialized query processing techniques. Here's an overview of the key steps and considerations involved in big data query processing:
- Data Ingestion
- Data Preparation
- Query Execution
- Parallel Processing
- Query Optimization
Overall, big data query processing requires a combination of distributed computing frameworks, specialized query processing techniques, optimization strategies, fault-tolerant mechanisms, and resource management techniques to effectively analyze and extract insights from large-scale datasets.
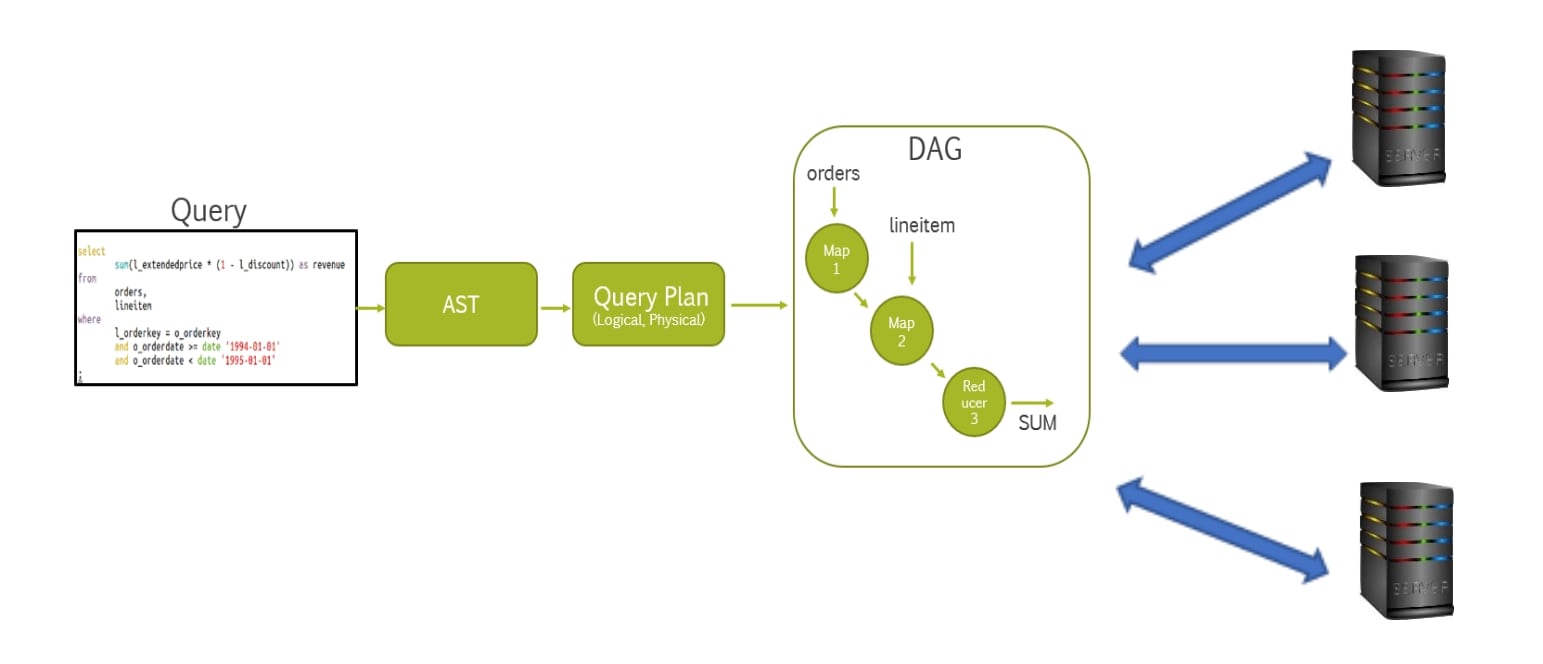
All query processors (Hive, Spark, Presto,…) follow almost same steps internally
- Create a DAG of operations and execute on cluster of machines.
- Differences are in input reading, in-memory/disk processing and cluster management.
Indeed, most query processors, including Hive, Spark, Presto, and others, follow a similar pattern of query execution, typically represented as a Directed Acyclic Graph (DAG) of operations. Here's an overview of how these query processors execute queries on a cluster of machines, highlighting the differences in input reading, in-memory/disk processing, and cluster management:
Query Parsing and Optimization: When a query is submitted, the query processor parses it, performs semantic analysis, and optimizes the query execution plan. This plan is represented as a DAG of operations, where each node represents a specific operation (e.g., scan, filter, join) and edges represent data flow dependencies between operations.
DAG Execution: The optimized query execution plan is then executed on a cluster of machines. Each node in the DAG represents a task or operation that needs to be performed. These tasks are scheduled and executed in parallel across multiple machines in the cluster.
Input Reading: Query processors differ in how they read input data. For example:
- Hive typically reads data from distributed storage systems like HDFS or cloud storage.
- Spark can read data from various sources including distributed file systems, databases, streaming sources, and more.
- Presto is designed to query data directly from distributed storage systems without needing to preprocess or load it into a separate storage format.
In-Memory/Disk Processing: Query processors may perform processing in-memory, on disk, or a combination of both:
- Spark often performs in-memory processing by caching intermediate data in memory between stages of computation. However, it can also spill data to disk if memory is insufficient.
- Hive typically performs disk-based processing, although it can leverage in-memory processing with optimizations like Tez or LLAP.
- Presto primarily performs in-memory processing, utilizing memory effectively across nodes in the cluster to minimize disk I/O and improve query performance.
Cluster Management: Query processors handle cluster management differently:
- Spark manages clusters through its built-in cluster manager (e.g., Spark Standalone, Apache Mesos, or Apache YARN), which allocates resources, schedules tasks, and monitors job execution.
- Hive relies on cluster managers like Apache YARN for resource management and job scheduling. Presto manages clusters using a coordinator node and multiple worker nodes. The coordinator node plans query execution and coordinates with worker nodes to execute tasks in parallel.
- Overall, while the basic principles of DAG execution are shared among query processors, differences arise in how they handle input reading, in-memory/disk processing, and cluster management. Understanding these differences is crucial for selecting the right query processor for specific use cases and optimizing query performance in big data environments.
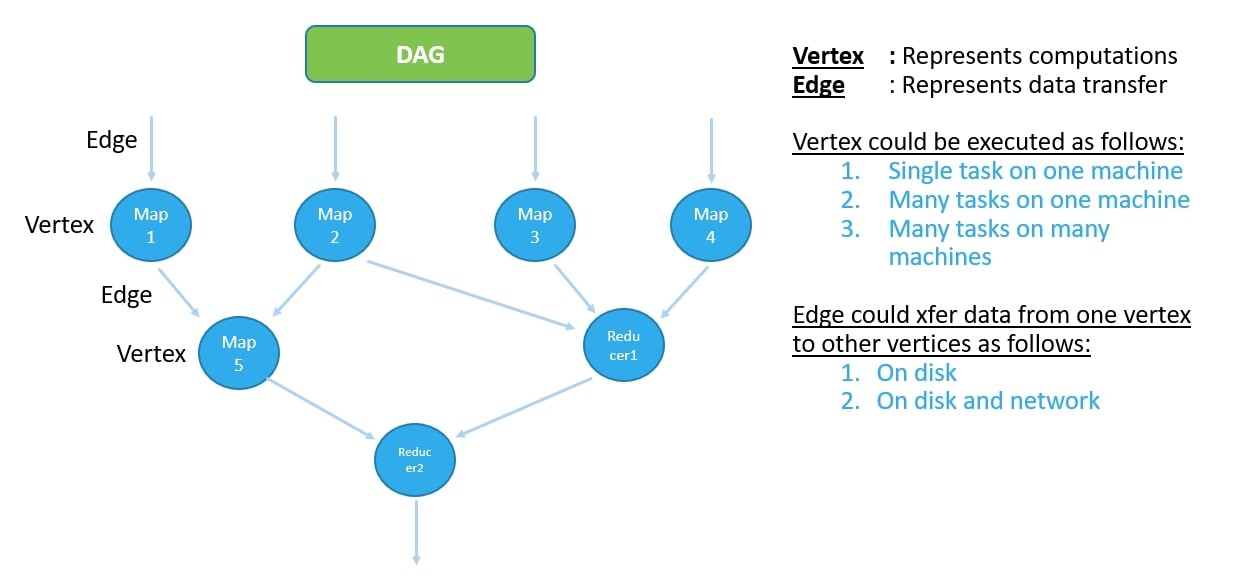
DAG: Represents Computations and Data Transfer
In the context of query processing, a Directed Acyclic Graph (DAG) represents both the computations and the data transfer between them.
DAGs provide a structured representation of the computations and data dependencies involved in query processing, enabling efficient and parallel execution of complex queries on distributed computing platforms. They serve as a blueprint for optimizing and orchestrating query execution, ensuring that computations are performed in a coordinated and efficient manner to achieve desired outcomes.
Overall, Spark SQL engine serves as the core component of its database system, responsible for interpreting SQL queries, optimizing query execution, managing data access, ensuring data integrity, and providing a seamless interface for users to interact with the database. It plays a critical role in enabling efficient and reliable data management and query processing in various application domains.
Figure below shows steps involved in the processing of a query within Spark.
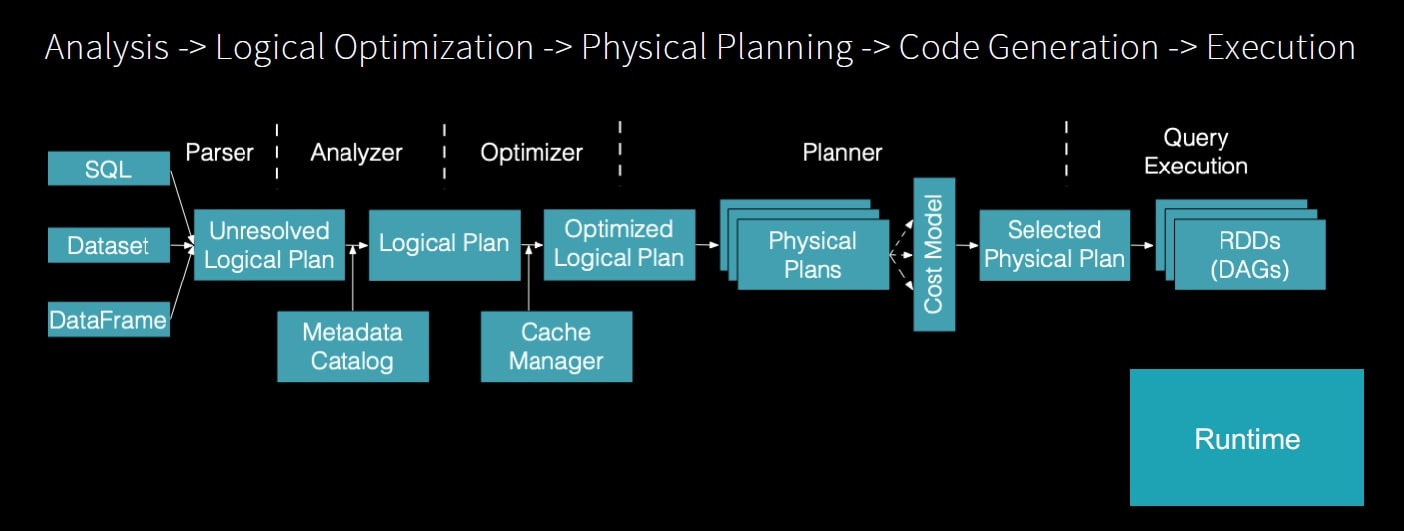
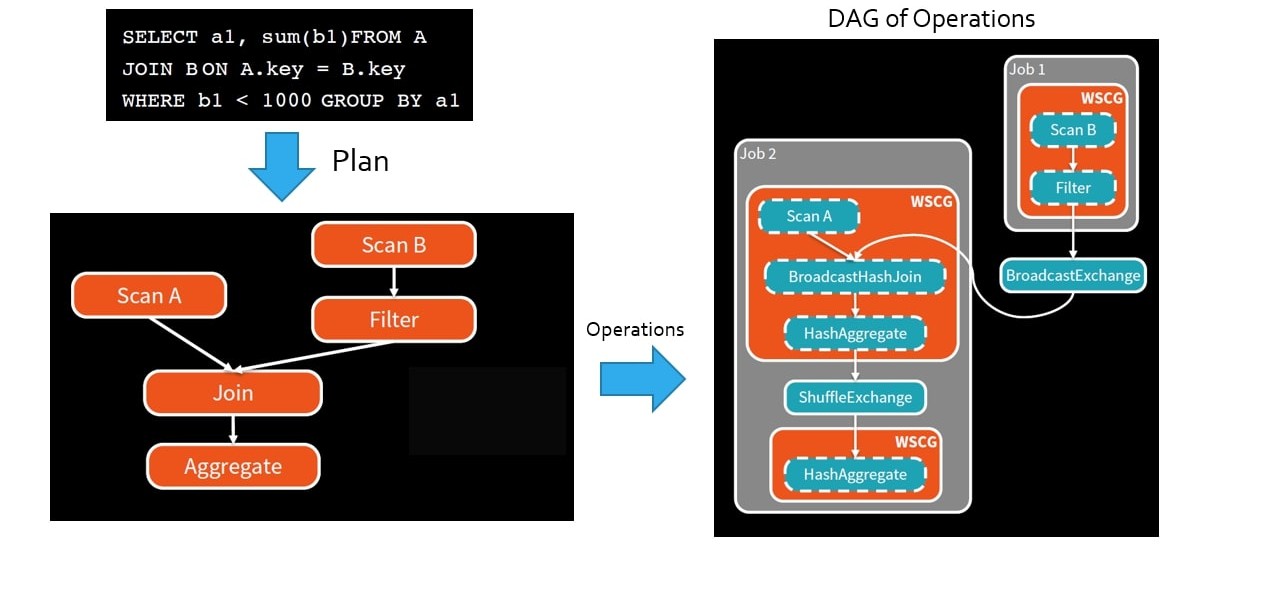
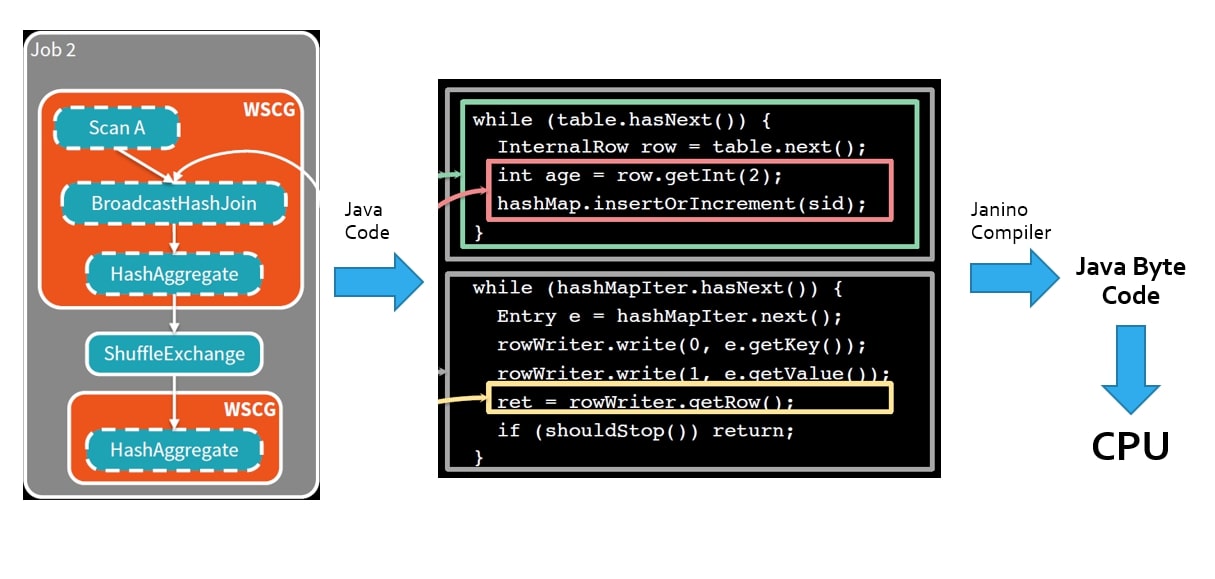
Operations become Java Code
In a SQL engine, the execution plan generated for a SQL query is typically translated into executable code, often in Java or another programming language, to perform the actual operations required to execute the query. Here's how this process generally works:
Execution Plan Generation: When a SQL query is submitted to the SQL engine, the engine performs query parsing, analysis, and optimization to generate an execution plan. This plan outlines the sequence of operations needed to execute the query efficiently, such as table scans, index lookups, join operations, filtering, aggregation, and sorting.
Code Generation: Once the execution plan is optimized, the SQL engine translates the plan into executable code. This code is typically generated in a programming language such as Java, C++, or another language suitable for the execution environment. Java is a common choice due to its widespread use, platform independence, and performance characteristics.
Mapping to Operators: Each node or operation in the execution plan is mapped to a corresponding operator or function in the generated code. For example, a table scan operation may be mapped to a method that reads data from a database table, while a join operation may be mapped to a method that performs a join between two datasets.
Compilation and Optimization: The generated code is then compiled and optimized to improve performance and resource utilization. Compiler optimizations may include code inlining, loop unrolling, dead code elimination, and other techniques to reduce overhead and improve execution speed.
Runtime Execution: Once the code is compiled and optimized, it is executed at runtime to perform the actual query processing. The generated code interacts with the underlying storage layer to read and manipulate data, apply query filters and transformations, perform computations, and generate query results.
Dynamic Code Generation: In some cases, SQL engines may employ dynamic code generation techniques to generate code dynamically at runtime based on the specific query and execution context. This allows the engine to adapt the code generation process to optimize performance and resource usage dynamically.
Overall, translating SQL execution plans into executable code allows SQL engines to efficiently execute complex queries and data processing tasks, leveraging the performance benefits of compiled code and platform-specific optimizations. This process enables efficient query execution and data processing in a wide range of database systems and analytical platforms.
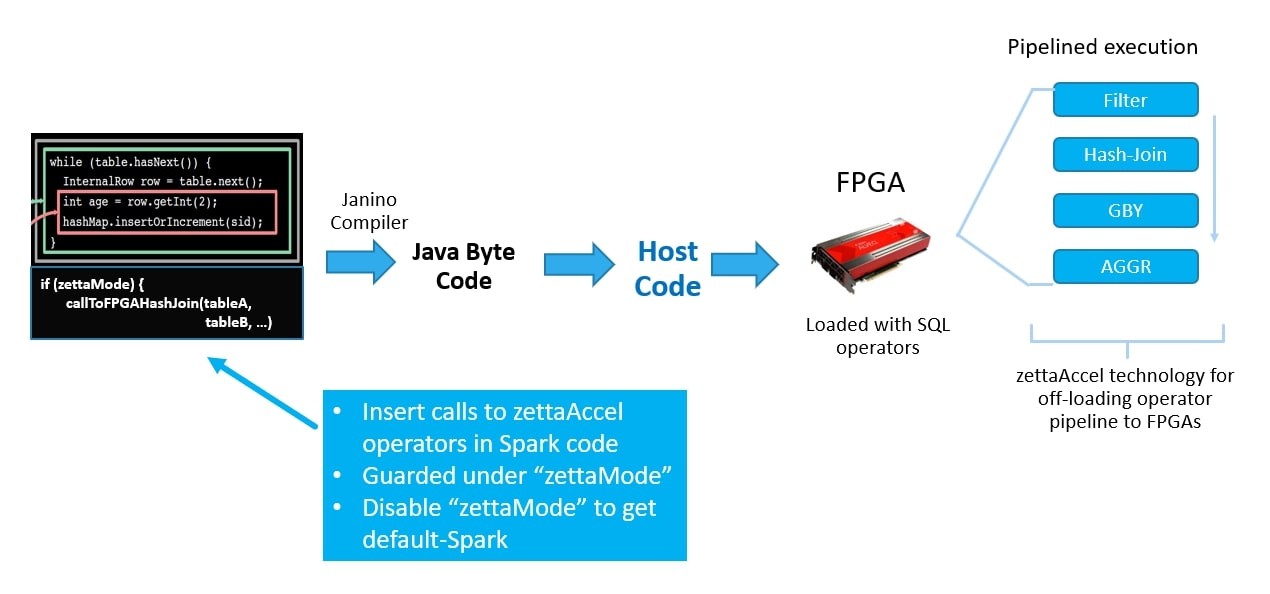
Process For Hash JOIN Operator
This is a basic implementation of a hash join operator in Spark. In practice, Spark SQL engine may use more sophisticated algorithms and optimizations to perform hash joins efficiently, especially for large datasets.
Proposed Flow for Acceleration
When integrating FPGA (Field-Programmable Gate Array) acceleration into the query processing flow, several additional steps and considerations need to be taken into account. Below is a proposed flow for accelerating query processing using FPGA:
Query Parsing and Optimization: Parse incoming SQL queries and optimize the query execution plan as usual.
Identify compute-intensive tasks suitable for offloading to FPGA acceleration.
DAG Generation: Generate a Directed Acyclic Graph (DAG) representing the optimized query execution plan, including FPGA-accelerated tasks.
Code Generation with FPGA Support: Translate the DAG into executable code, integrating FPGA-specific optimizations and offloading compute-intensive tasks to FPGA accelerators.
Generate FPGA bitstreams for executing accelerated tasks on FPGA hardware.
Hardware Configuration and Deployment: Configure FPGA hardware accelerators with the generated bitstreams.
Deploy FPGA resources in the cluster, ensuring proper integration with the query processing pipeline.
Parallel Execution with FPGA Offloading: Distribute the generated code across multiple nodes in the cluster, including FPGA-accelerated tasks.
Utilize parallel processing capabilities to execute both CPU and FPGA-accelerated tasks concurrently.
Data Transfer and FPGA Communication: Optimize data transfer mechanisms between CPU and FPGA accelerators to minimize latency and maximize throughput.
Implement efficient communication protocols and data exchange interfaces between CPU and FPGA.
Operator Execution with FPGA Acceleration: Execute compute-intensive tasks on FPGA accelerators, offloading processing from CPU cores.
Leverage FPGA hardware to accelerate specific operations such as filtering, aggregation, sorting, or custom user-defined functions (UDFs).