Legacy Hive to Spark Migration
Problem Staement
A prominent US based online retailer currently relies on legacy Hive infrastructure for their ETL processes.
Challenge
They face significant challenges due to performance limitations, scalability issues, and the inability to derive real-time insights from their data. To address these challenges, the ecommerce client aims to migrate their ETL processes from Hive to Spark on AWS cloud.
Solution
Migration Strategy
The migration strategy includes a systematic approach to assess, plan, and execute the transition from Hive to Spark:
- Assessment: Evaluate current Hive infrastructure, performance benchmarks, and resource utilization.
- Data Profiling: Identify key data sources, dependencies, and migration requirements.
- Migration Plan: Develop a phased migration plan to ensure data integrity and minimize disruptions.
- Testing: Validate migrated processes for accuracy, performance, and compatibility with Spark.
- Deployment: Implement Spark for ETL and analytics, leveraging AWS cloud services.
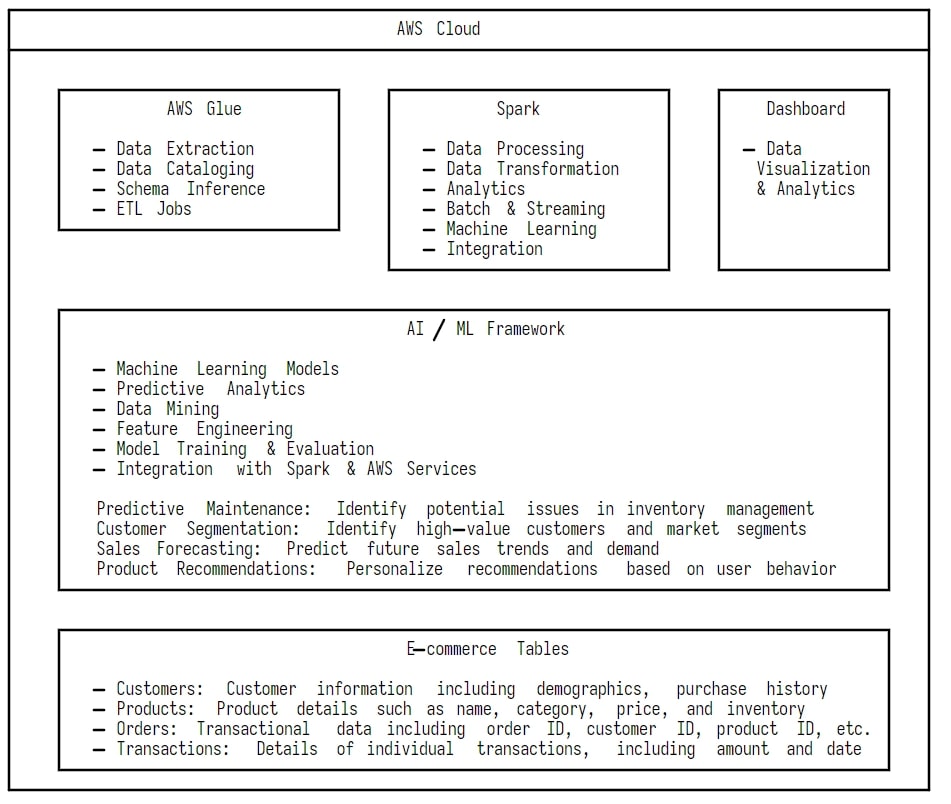
The execution plan involves the following key steps:
- Data Extraction and Transformation: Utilize Spark SQL and DataFrame APIs to extract and transform data from various sources.
- Integration with Python Feature Engineering: Migrate existing Python-based feature engineering pipelines to PySpark.
- Performance Monitoring: Implement monitoring and logging frameworks to track Spark job performance and data quality metrics.
- Integration with Existing Dashboarding: Ensure compatibility and seamless integration of Spark-generated data with existing dashboards and BI tools.
- Deployment and Optimization: Deploy Spark clusters and optimize configurations for performance and scalability.
Result
This migration from Hive to Spark on AWS cloud empowers XYZ E-commerce with enhanced analytics capabilities, improved performance, and scalability enabling them to thrive in the competitive e-commerce landscape.
- Performance Improvement: Spark enables faster data processing and analytics, reducing ETL times.
- Cost Optimization: Optimized resource utilization and managed services on AWS reduce infrastructure costs.
- Real-time Insights: Spark's capabilities facilitate real-time analytics and insights, enhancing decision-making processes.
- Scalability: Spark's distributed architecture allows for seamless scalability to handle growing data volumes and demands.
Impact
The migration to Spark on AWS cloud delivered significant financial and performance benefits as it resulted in cost optimization and operational efficiencies.
