GPU: The Driving Force behind ChatGPT!

GPU: Graphics Processing Unit
Indeed, GPUs have evolved significantly over the past decades and have become integral in various computing applications beyond just graphics processing.
Acceleration of Graphics: Originally designed for rendering graphics, GPUs have been used extensively in applications such as image processing, video encoding/decoding, and gaming due to their ability to handle parallel processing tasks efficiently.
Co-processor to CPU: GPUs typically function as co-processors alongside CPUs, offloading parallelizable tasks from the CPU to the GPU for faster execution. This parallel processing capability complements the sequential processing nature of CPUs, resulting in overall performance improvements.
SIMD Architecture: GPUs are characterized by their SIMD (Single Instruction, Multiple Data) architecture, which allows them to execute the same instruction on multiple data elements simultaneously. This makes GPUs highly efficient for tasks that can be parallelized, such as matrix operations, convolution neural networks (CNNs), and simulations.
Suitability for Data-Intensive Applications: GPUs excel in scenarios where a few operations need to be performed over vast amounts of data, thanks to their parallel processing capabilities. This includes tasks like data analytics, machine learning, scientific computing, and cryptographic calculations.
Availability on Cloud Platforms: GPUs are readily available on major cloud platforms like Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), and others. Cloud-based GPU instances allow users to access high-performance computing resources on-demand, making them accessible to a wide range of applications and users.
Overall, GPUs have become indispensable in modern computing ecosystems, offering significant performance gains and enabling breakthroughs in various fields ranging from artificial intelligence to scientific research. Their parallel processing capabilities make them well-suited for tackling data-intensive tasks efficiently.
GPU Architecture: Processors with 1000s of cores
GPUs can be thought of CPUs with thousands of cores working in parallel to finish any computation. Only change is the unlike a CPU core, GPU cores are equipped to handle very simple computations. You cannot boot up an OS (like Windows) on a GPU! Or you cannot run PowerPoint, Excel, Doc etc. on a GPU. But you can do matrix multiplications 1000x faster than what you can do on CPUs!
Figure below shows a typical CPU and GPU side by side. The CUDA Core is a very reduced version of a general purpose CPU core.
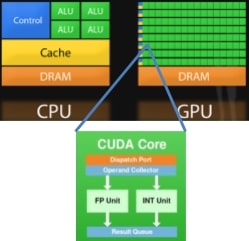
Running a program on GPU
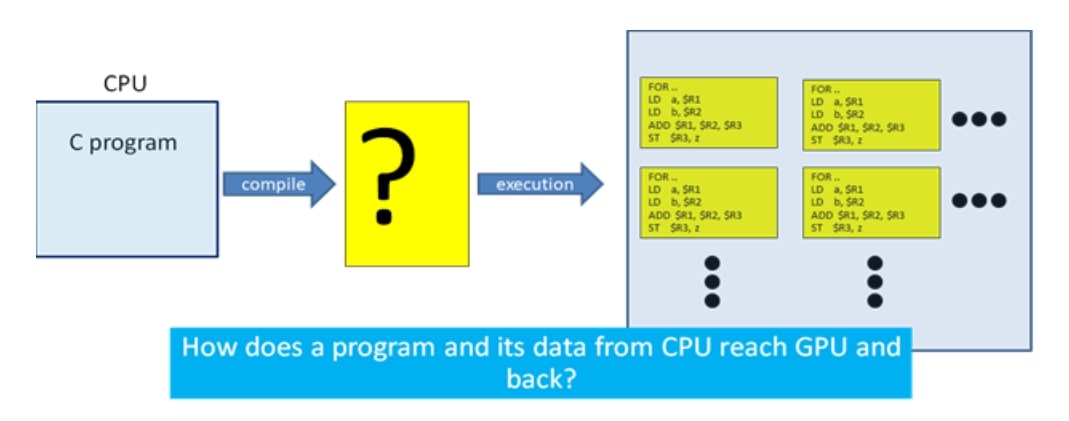
GPUs need CPU to perform their task. The orchestration of compute flow is still CPU's responsibility. Steps involved in offloading a computation to CPU are very simple and they are shown in the figure below.
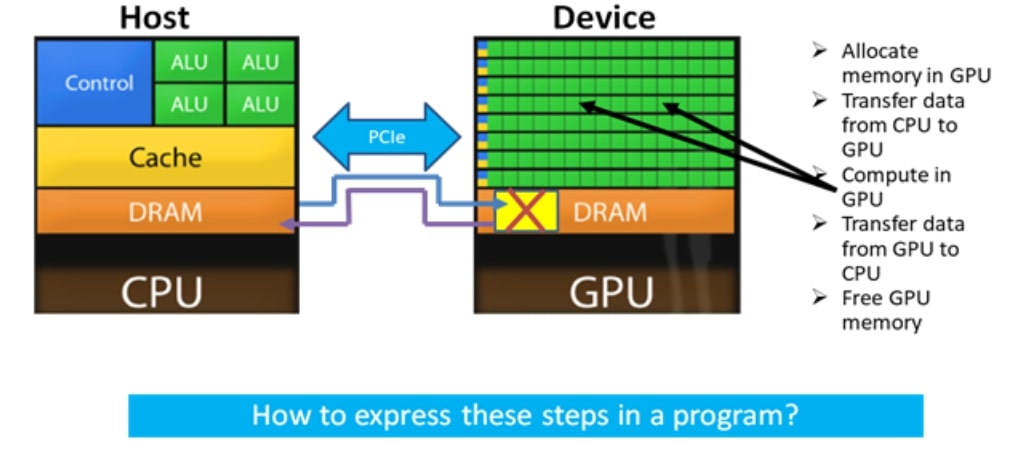
Key thing to understand is that how these steps would be achieved through a program. Are regular programming languages sufficient? Or any extensions are required? This has been achieved by creation of CUDA which provides programming constructs to invoke these steps in a specified order.
CUDA: GPU Programming Language
Figure below shows a snapshot of CUDA language. It is very similar in look and feel to any other programming language. In addition, steps involved to invoke a GPU computation are embedded within the program.

Certainly, GPUs offer substantial speed-ups, especially for highly parallelizable applications.
Speed-Ups: GPUs can indeed provide significant speed-ups ranging from 10 to 100 times or even more for highly parallelizable applications compared to traditional CPU-based processing. This is primarily due to their massively parallel architecture, which allows them to execute a large number of computations simultaneously.
Minimal Data Dependencies: GPUs tend to perform exceptionally well when data dependencies are minimal or when tasks can be parallelized effectively. In such scenarios, the GPU can distribute workloads across its numerous processing cores, allowing for efficient parallel execution and achieving higher throughput compared to CPUs.
Sequential Computation within a Core: While GPUs excel at parallel processing, it's important to note that computation within a single core is still sequential. Each processing core within a GPU typically executes instructions sequentially, but the strength lies in the large number of cores working in parallel. Therefore, while individual core computation is sequential, the overall architecture enables massive parallelism, leading to significant performance gains.
In summary, GPUs are highly effective for tasks that can be parallelized, providing substantial speed-ups due to their massively parallel architecture. However, they perform best when data dependencies are minimal, allowing for efficient distribution of workloads across multiple cores. Despite the sequential nature of computation within a core, the overall parallel architecture of GPUs enables them to achieve remarkable performance enhancements for a wide range of applications.
