Accelerating SQL on Big Data
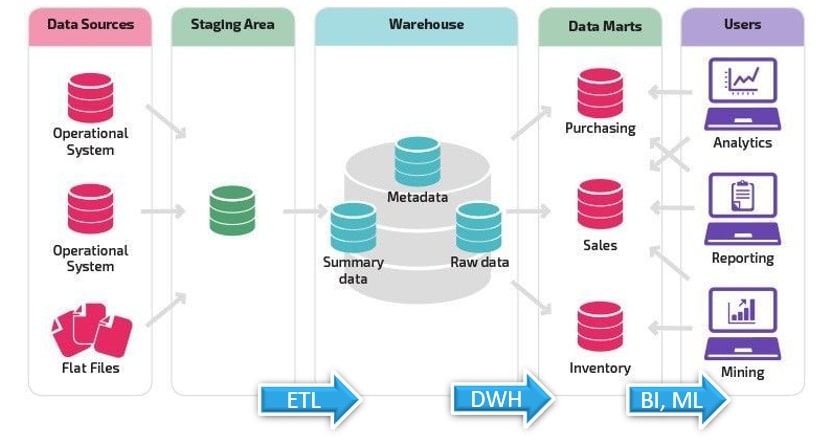
Query Processing is central to Data Pipelines
Data ingestion, translation, transfer and visualization, all require query (predominantly SQL based) processing. Accelerating SQL on big data has become increasingly challenging as query processing reaches its limits due to growing data volumes, complexity of queries, and resource constraints. To address these challenges and achieve performance improvements, several strategies and technologies have been employed:
- Distributed Processing
- Columnar Storage
- Data Partitioning
- Indexing
- In-Memory Processing
- Hardware Acceleration
- Advanced Analytics Engines
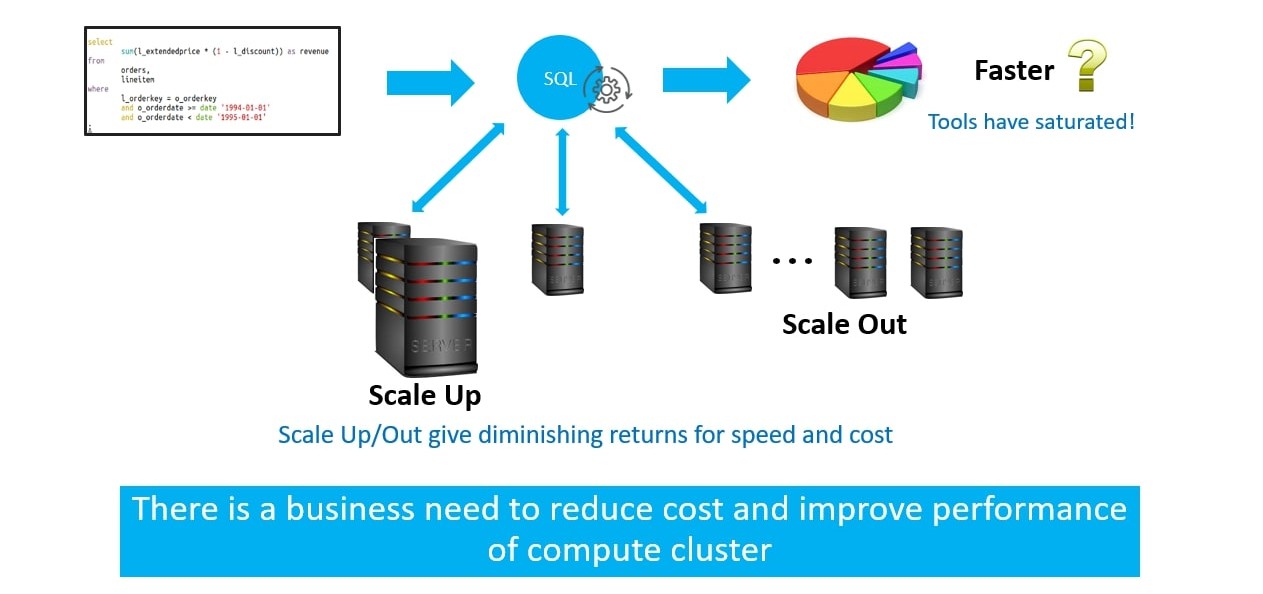
The most commonly used techniques of scaling up and scaling out start to give diminishing returns for cost and speed.
Solution : CPU + Hardware Acceleration!
Combining CPU with hardware acceleration is a powerful solution for accelerating SQL processing on big data.
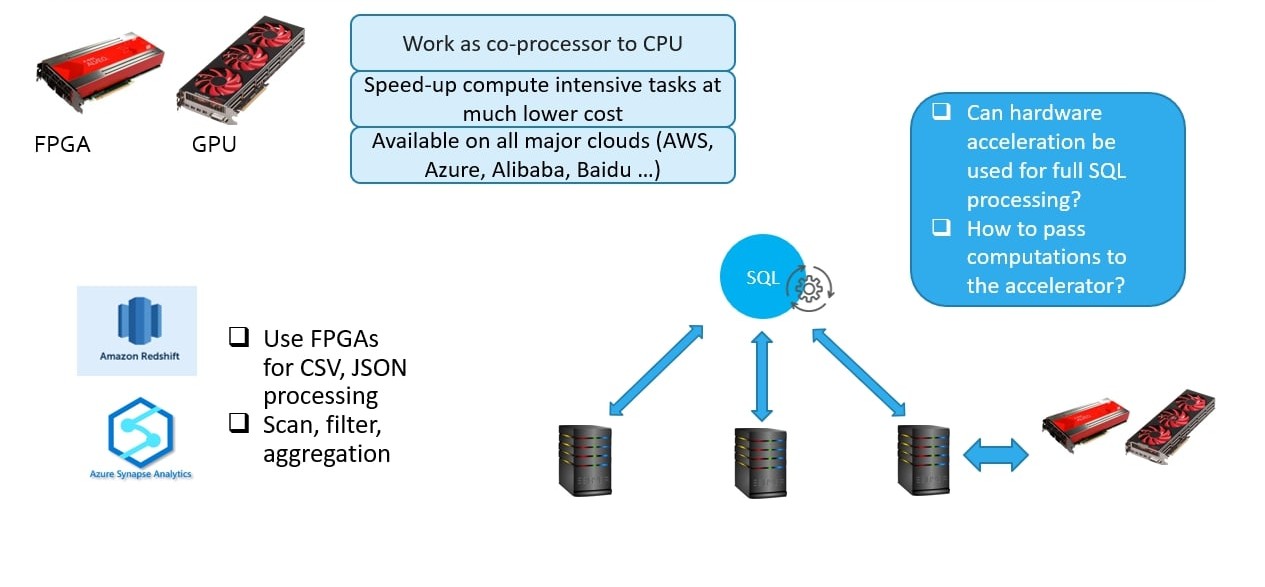
FPGAs have come up as a very good choice for hardware accelerators. They are already actively deployed into Amazon RedShift and Azure Synapse processing engines. In addition, GPUs have been providing similar capabilities for SQL acceleration.
To enable SQL Acceleration, we need: Offloading of Computations to Accelerators
To fulfill the need for offloading computations to accelerators such as GPUs or FPGAs, consider the following approach:
- Identify Compute-Intensive Tasks
- Select Appropriate Accelerator
- Integrate with SQL Processing Framework
- Decide on Partitioning and Offloading Strategy
By following these steps, you can effectively offload computations to accelerators such as GPUs or FPGAs, accelerating SQL processing and improving the overall performance and efficiency of your big data analytics workflows.
Figure below shows internal workings of Hive based query processing engine. SQL is converted to a DAG in the main node which gets transferred to compute nodes (with pre-loaded table data). Each node does its computation and then the result is passed back to main node.
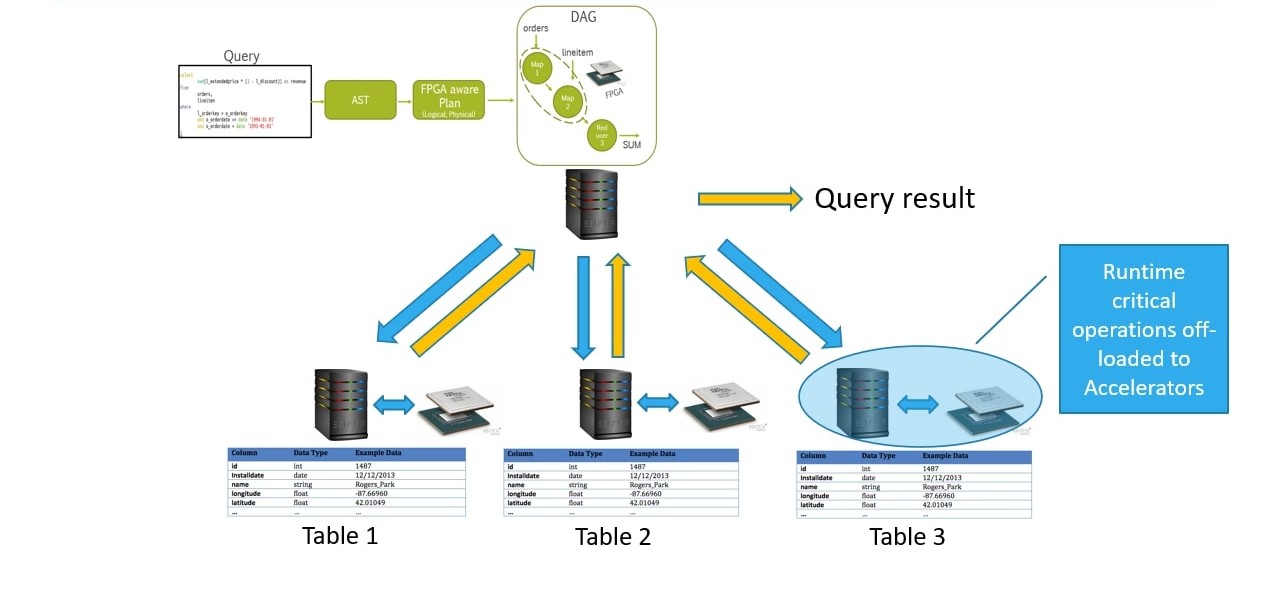
If we need to integrate a hardware accelerator then it needs to be done on the compute nodes. We need a middle-ware which can do the communication between compute nodes and the accelerator. Figure below shows ZettaAccel middleware which acts as the intermediary.
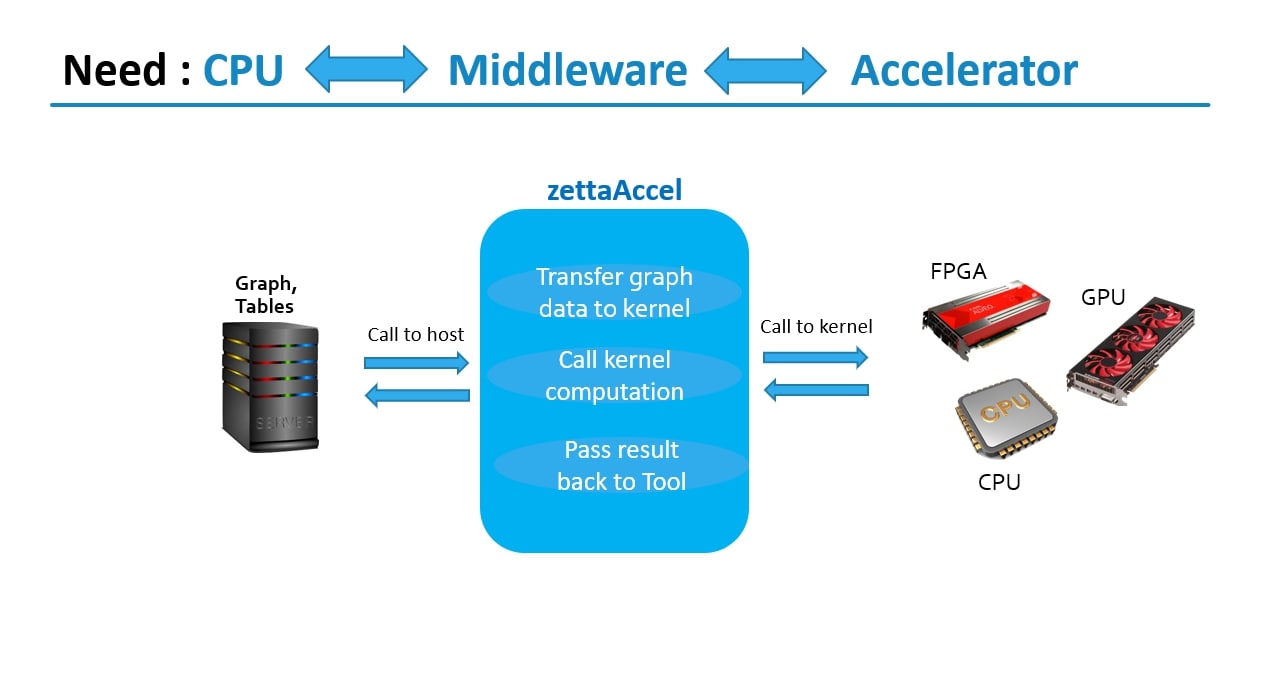
ZettaAccel Middleware: Accelerator Aware Design
For an efficient workflow involving ZettaAccel Middleware with Accelerator Aware Design, you would focus on optimizing the interaction between the CPU, middleware, and accelerator, ensuring that the middleware is aware of the accelerator's capabilities and can effectively utilize its resources. Here's what ZettaAccel achieves:
- Accelerator Discovery and Initialization
- Resource Allocation and Management
- Accelerator-Aware Task Partitioning
- Data Transfer Optimization
- Kernel and Algorithm Functionality
- Error Handling and Recovery
Overall, ZettaAccel offers a comprehensive solution for accelerating big data and graph query processing, combining the power of hardware accelerators with optimized software components and customizable models to deliver exceptional performance and efficiency.
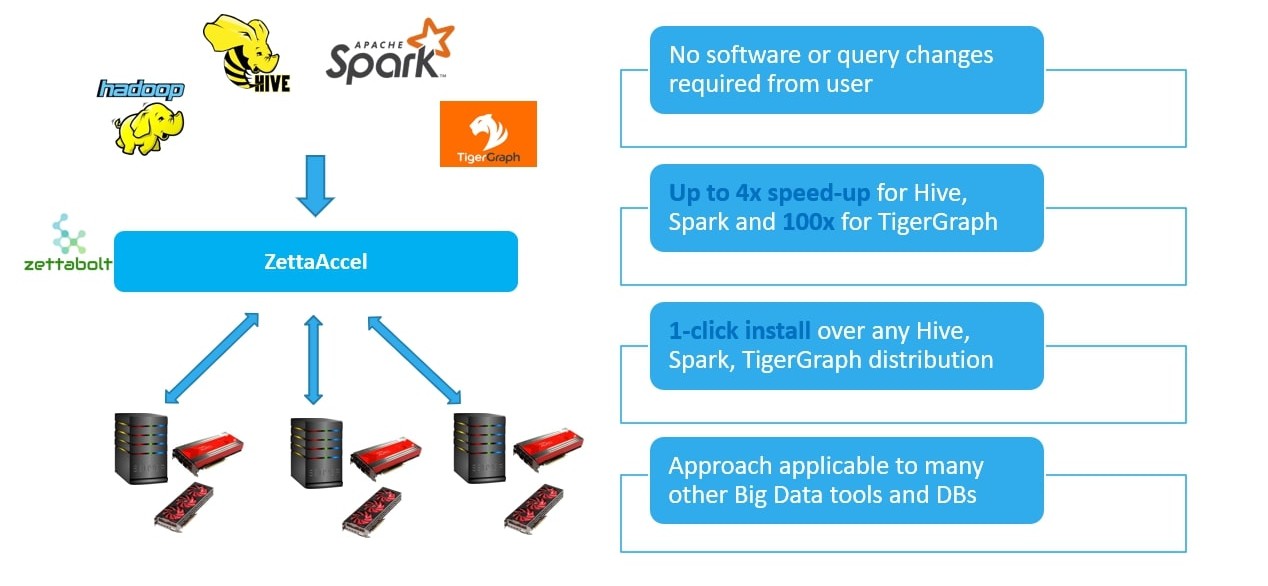
Our Differentiation:
Non-intrusive Deployment: ZettaAccel offers a non-intrusive deployment model, allowing organizations to integrate it seamlessly with their existing BI solutions without requiring extensive changes to their software stack or workflows. This enables a smooth transition and minimizes disruption to ongoing operations.
Compatibility with Established BI Solutions: Unlike many CPU-only and GPU/FPGA based BI acceleration products that necessitate significant modifications to existing software and workflows, ZettaAccel can co-exist harmoniously with established BI solutions from Apache OSS, Cloudera, AWS, Azure, and others. This compatibility ensures that organizations can leverage the benefits of accelerated query processing without overhauling their existing infrastructure.
TCO Savings and Business Impact: ZettaAccel delivers significant TCO savings, with potential reductions of over 40% translating into millions of dollars in savings for large enterprise customers. This substantial cost reduction positively impacts the bottom line and enhances the overall financial health of organizations.
No Replacement Cycle Limitations: Unlike solutions that require replacing existing infrastructure, ZettaAccel does not impose limitations based on replacement cycles. By seamlessly integrating with established solutions, it accommodates organizations' long-term investment in their BI ecosystems, ensuring flexibility and adaptability to evolving business needs.
In summary, ZettaAccel's differentiation lies in its non-intrusive deployment model, compatibility with established BI solutions, significant TCO savings, and flexibility regarding replacement cycles. These factors contribute to its appeal and value proposition for enterprise customers seeking to enhance the performance and efficiency of their BI and analytics workflows.

Hive Acceleration Results
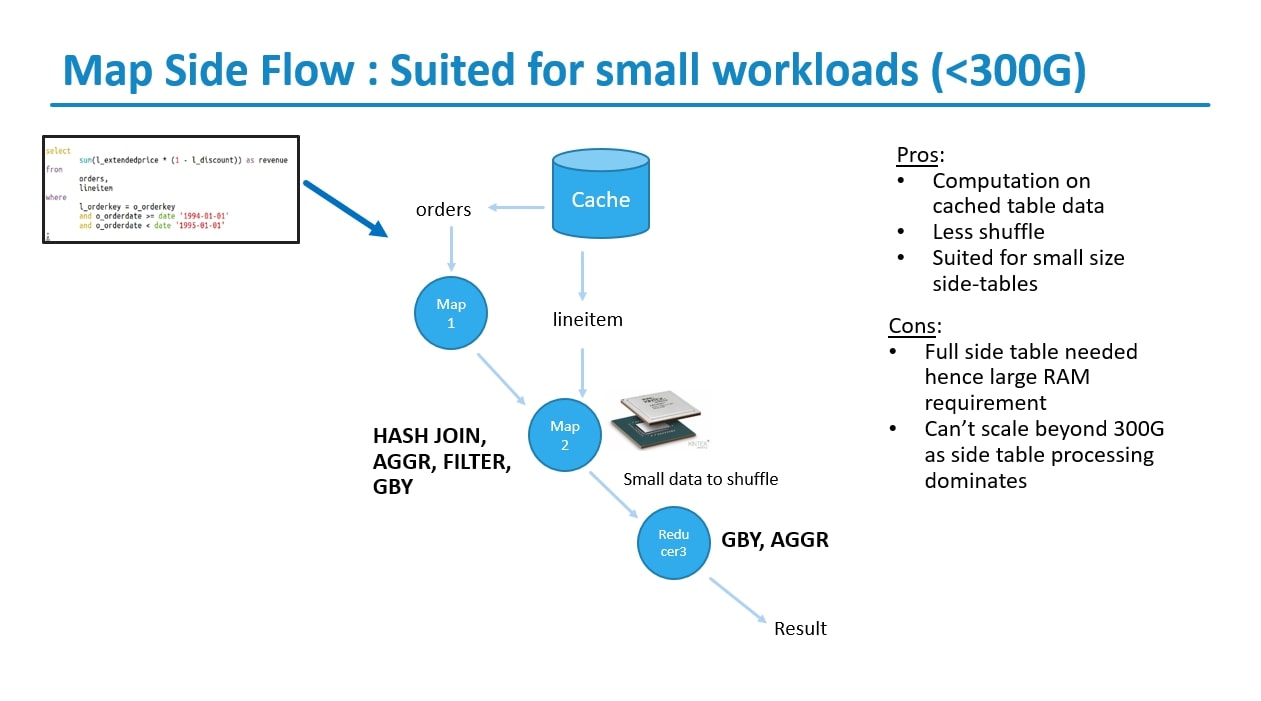
Map Side Flow: Suited for small workloads (<300G)
The Hive acceleration results for Map Side Flow, which is best suited for small workloads (<300G), exhibit both advantages and limitations:
Pros:
Computation on Cached Table Data: Map Side Flow allows computation to be performed directly on cached table data, eliminating the need for extensive data movement and reducing processing overhead.
Less Shuffle: With Map Side Flow, there is less shuffle compared to other processing flows in Hive, leading to reduced network traffic and faster query execution times, especially for small datasets.
Suited for Small Size Side-Tables: This approach is particularly well-suited for scenarios involving small size side-tables, where the data can be efficiently processed within memory without the need for extensive disk I/O operations.
Cons:
Large RAM Requirement: The main downside of Map Side Flow is its requirement for a full side table to be loaded into memory. This necessitates a large amount of RAM, especially for larger datasets, which can pose challenges for systems with limited memory resources.
Limited Scalability: Map Side Flow becomes less effective for larger datasets as the size of the side table increases. Beyond a certain threshold (in this case, 300G), the overhead of loading the entire side table into memory dominates the processing, leading to diminished performance and scalability.
In summary, while Map Side Flow offers advantages such as computation on cached table data, reduced shuffle, and suitability for small size side-tables, it also has limitations related to its large RAM requirement and limited scalability for larger datasets. Organizations should carefully consider their workload characteristics and resource constraints when deciding whether to adopt Map Side Flow for accelerating Hive queries.
TPC-H Queries, 300G Data (Map Side Flow)
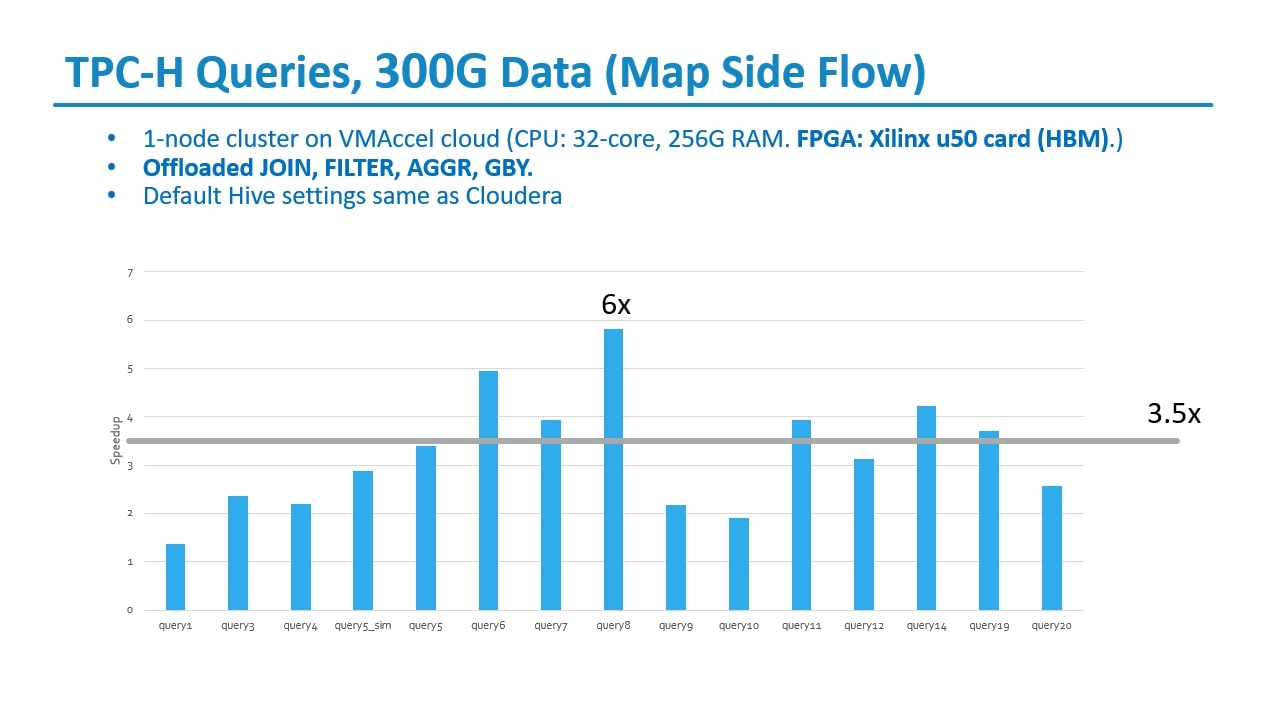
Reduced Side Flow: For larger workloads (Terabyte+) In the context of TPC-H queries with a 300G dataset using Map Side Flow in Hive, here's a breakdown of the pros and cons:
Pros:
Computation on Cached Table Data: Map Side Flow allows computation to be performed directly on cached table data, leveraging the benefits of in-memory processing. This results in faster query execution times compared to scenarios where data needs to be fetched from disk.
Less Shuffle: With Map Side Flow, there is reduced shuffle compared to other processing flows in Hive. This minimizes network traffic and data movement across nodes, leading to improved query performance, especially for join-heavy queries.
Suited for Small Size Side-Tables: Map Side Flow is well-suited for scenarios involving small size side-tables. In such cases, the side-table data can be efficiently processed within memory, reducing the need for disk I/O operations and improving overall query efficiency.
Cons:
Large RAM Requirement: The main downside of Map Side Flow is its requirement for a full side table to be loaded into memory. This necessitates a large amount of RAM, especially for larger datasets, which can pose challenges for systems with limited memory resources.
Limited Scalability: Map Side Flow becomes less effective for larger datasets as the size of the side table increases. Beyond a certain threshold (in this case, 300G), the overhead of loading the entire side table into memory dominates the processing, leading to diminished performance and scalability.
In summary, while Map Side Flow offers advantages such as computation on cached table data, reduced shuffle, and suitability for small size side-tables, it also has limitations related to its large RAM requirement and limited scalability for larger datasets. Organizations should carefully consider their workload characteristics and resource constraints when deciding whether to adopt Map Side Flow for accelerating Hive queries.
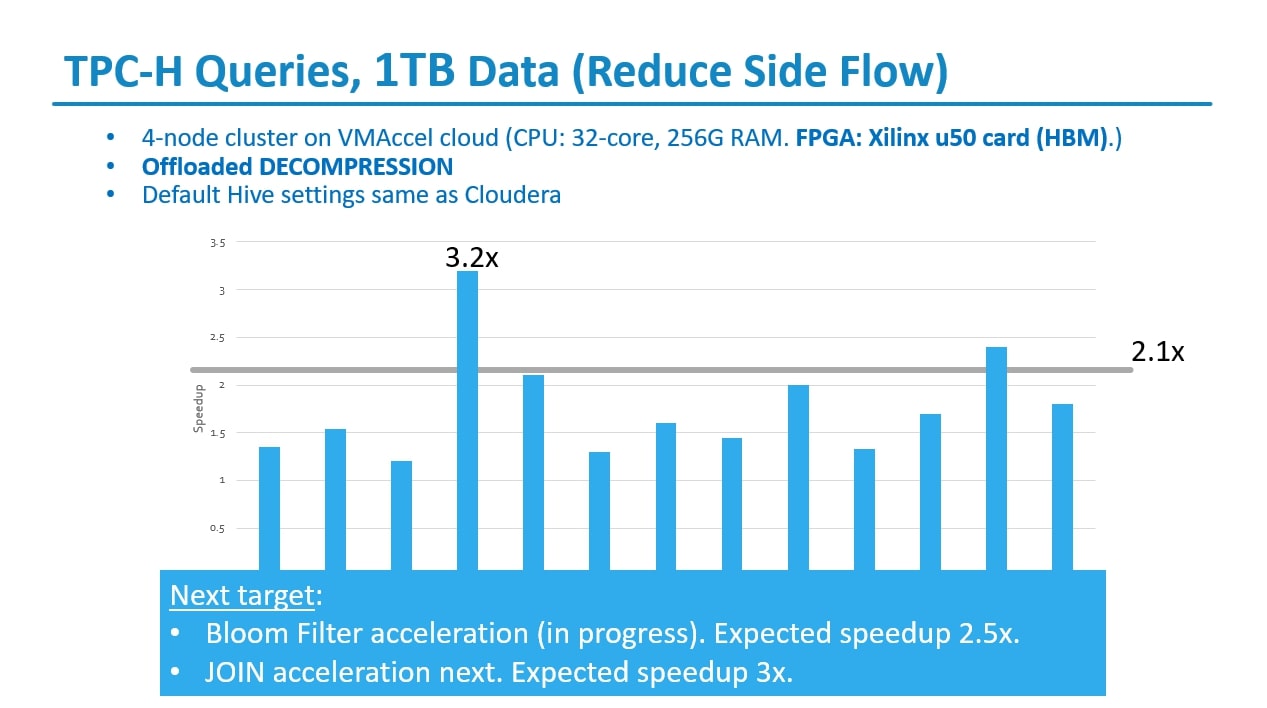
TPC-H Queries, 1TB Data (Reduce Side Flow)
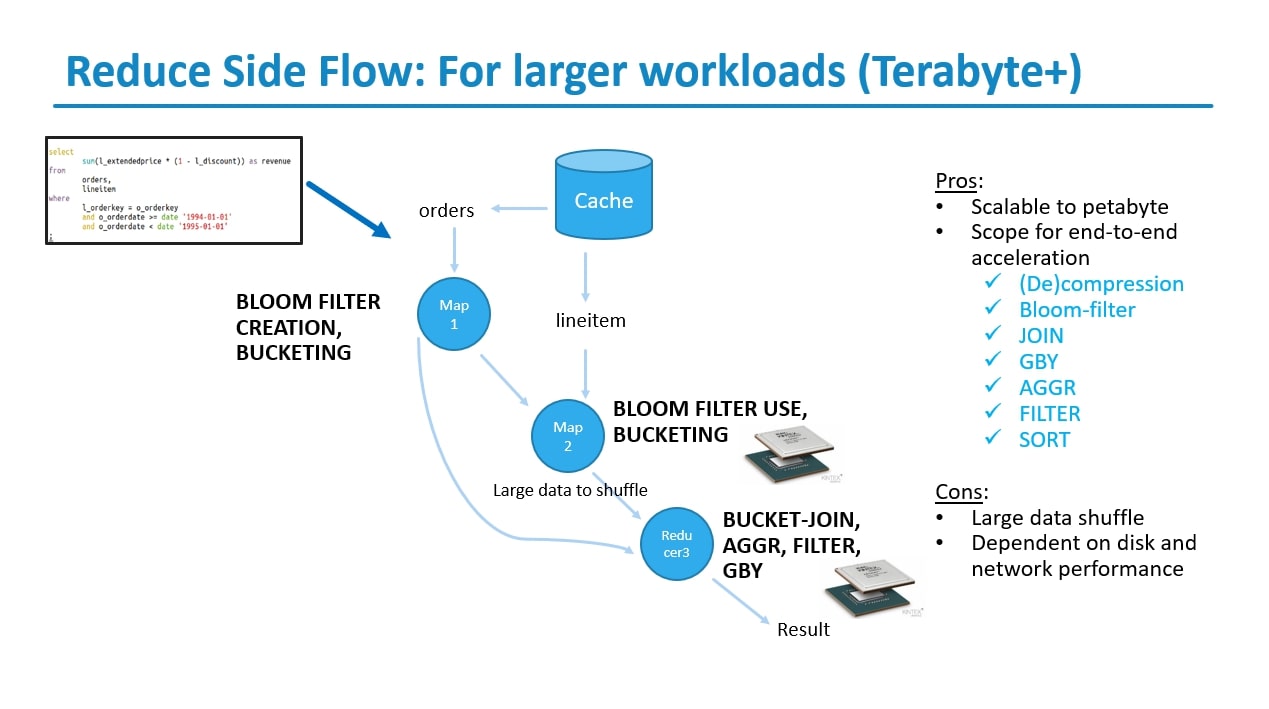
For TPC-H queries with a 1TB dataset using Reduce Side Flow in Hive on a 4-node cluster on VMAccel cloud with specific hardware specifications (CPU: 32-core, 256GB RAM, FPGA: Xilinx U50 card with HBM), with the offloading of DECOMPRESSION, here's an analysis of the setup:
Pros:
Scalability: Reduce Side Flow, combined with a 4-node cluster, provides increased scalability compared to a single-node setup. With more nodes available for parallel processing, the system can handle larger volumes of data efficiently, leading to improved performance and reduced query execution times.
Offloaded Decompression: Offloading the decompression task to the FPGA accelerator enables efficient processing of compressed data directly on the hardware, reducing CPU overhead and accelerating query execution. This is particularly beneficial for scenarios involving large datasets where data compression is commonly used to reduce storage requirements and improve I/O performance.
Resource Utilization: The combination of CPU and FPGA resources across multiple nodes allows for efficient utilization of compute and memory resources. Each node contributes to parallel query processing, while the FPGA accelerators handle specific tasks such as decompression, optimizing overall system performance and resource utilization.
Cons:
Hardware Configuration and Management: Managing a multi-node cluster with FPGA accelerators requires careful configuration and coordination to ensure proper hardware integration and resource allocation. This includes setting up network connectivity, distributing data across nodes, and managing FPGA resources effectively to achieve optimal performance.
Data Distribution and Communication Overhead: In a distributed environment, data distribution and communication overhead can impact query performance, especially for operations involving inter-node data transfer. Minimizing data movement and optimizing data locality are critical for reducing latency and maximizing throughput in a multi-node setup.
Complexity of FPGA Offloading: Offloading decompression tasks to FPGA accelerators requires expertise in FPGA programming and hardware design. Developing and optimizing FPGA-accelerated decompression pipelines may entail significant complexity, including implementing efficient compression algorithms, memory management, and data transfer mechanisms.
Cost Considerations: Deploying and managing a multi-node cluster with FPGA accelerators involves additional costs related to hardware, software licenses, infrastructure, and maintenance. Organizations need to evaluate the cost-effectiveness of the solution against the expected performance benefits and business requirements.
In summary, leveraging Reduce Side Flow with offloaded decompression tasks on a 4-node cluster with FPGA accelerators offers scalability, improved performance, and efficient resource utilization. However, it requires careful configuration, management, and optimization to ensure successful implementation and maximize the benefits of distributed query processing with FPGA acceleration.
TCO Savings: For a 2X increase in query throughput around 30% TCO savings
For a scenario where there is a 2X increase in query throughput, accompanied by approximately 30% TCO (Total Cost of Ownership) savings, the cost savings can be attributed to several factors
Hardware Utilization: By doubling the query throughput without significantly increasing hardware infrastructure, organizations can achieve better utilization of existing resources. This means that the same hardware infrastructure (e.g., servers, storage, networking) can handle twice the workload, leading to cost savings in terms of hardware acquisition and maintenance.
Efficiency Gains: Improved query throughput often implies more efficient use of computational resources, including CPU, memory, and storage. Optimized query processing algorithms, parallelization techniques, and hardware acceleration can lead to faster query execution times and reduced resource idle time, resulting in cost savings by maximizing resource efficiency.
Overall, achieving a 2X increase in query throughput with around 30% TCO savings indicates significant improvements in efficiency, resource utilization, and operational effectiveness. Organizations can leverage these cost savings to reinvest in innovation, growth initiatives, or further optimization efforts to continuously improve their data processing capabilities while maintaining cost efficiency.
