Evaluating Intel OAP For Spark Acceleration

In this whitepaper we study Intel OAP's Gazelle component, how it integrates with Spark, the methodologies used to evaluate its performance, the significance of the results in terms of real-world big data processing tasks, and the implications for users seeking to optimize Spark-based analytics workflows. Intel OAP's Gazelle Plug-in: Intel has developed a plug-in called Gazelle specifically for Apache Spark. A plug-in is an additional software component that enhances or extends the functionality of an existing software application, in this case, Spark. Intel OAP (Optimized Analytics Package) refers to a suite of tools or libraries optimized by Intel for big data analytics tasks. Intel OAP, written using C++ is very suited for SQL acceleration as it provides following advantages:
- Columnar processing using AVX512 instructions.
- Optimized shuffle, compute.
- Suited for FPGA/GPU based hardware acceleration
Intel OAP Project
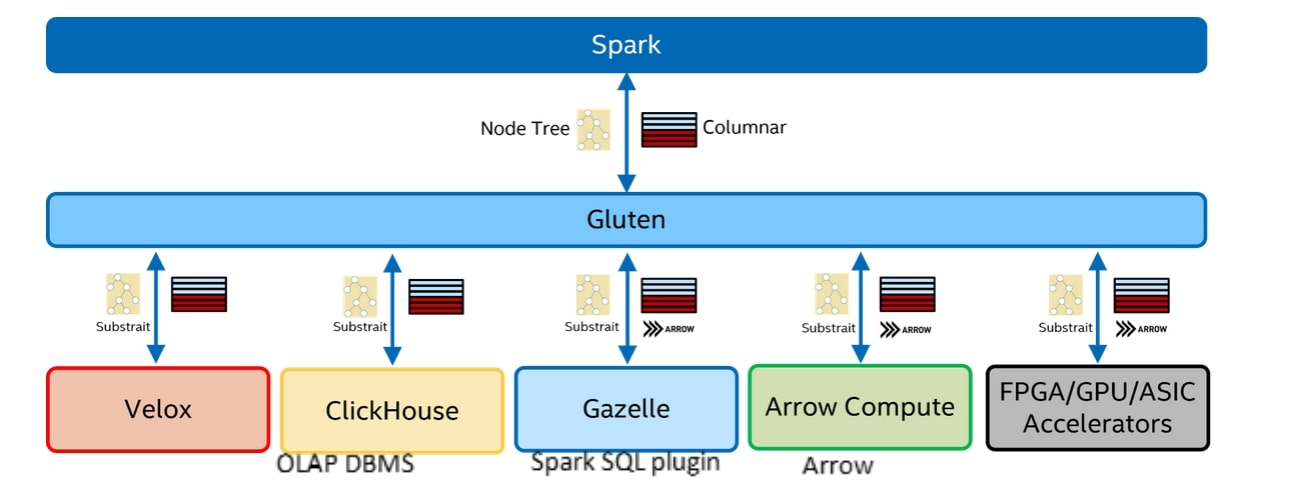
How to install Intel OAP on Open Source Spark
Provide additional jars during launch of Spark shell: To make Intel OAP easy to install on open-source Spark and provide additional JARs during the launch of the Spark shell, you can follow these general steps:
Download Intel OAP Package: Obtain the Intel OAP package from the official Intel website or from a trusted source.
Prepare Spark Environment: Ensure you have a working installation of Apache Spark on your system. If not, download and set up Spark according to your operating system and requirements.
Integrate Intel OAP JARs: Place the required Intel OAP JAR files in a directory accessible by your Spark environment. These JAR files typically include the libraries necessary for Intel OAP's optimizations and enhancements.
Update Spark Configuration: Modify the Spark configuration to include the Intel OAP JARs during the launch of the Spark shell. This can typically be done by setting the spark.driver.extraClassPath and spark.executor.extraClassPath properties in the Spark configuration files (spark-defaults.conf or spark-env.sh).
Launch Spark Shell: Once the configuration is updated, launch the Spark shell as you normally would. The additional Intel OAP JARs will be included in the classpath, allowing Spark to utilize the optimizations provided by Intel OAP.
Verify Installation: After launching the Spark shell, you can verify that Intel OAP is successfully integrated by:
${SPARK_HOME}/bin/spark-shell
--verbose
--master yarn
--driver-memory 10G
--conf spark.plugins=com.intel.oap.GazellePlugin
--conf spark.driver.extraClassPath=$PATH_TO_JAR/gazelle-plugin-1.4.0-spark-3.2.1.jar
--conf spark.executor.extraClassPath=$PATH_TO_JAR/gazelle-plugin-1.4.0-spark-3.2.1.jar
--conf spark.shuffle.manager=org.apache.spark.shuffle.sort.ColumnarShuffleManager
--conf spark.driver.cores=1
--conf spark.executor.instances=12
--conf spark.executor.cores=6
--conf spark.executor.memory=20G
--conf spark.memory.offHeap.enabled=true
--conf spark.memory.offHeap.size=20G
--conf spark.task.cpus=1
--conf spark.locality.wait=0s
--conf spark.sql.shuffle.partitions=72
--conf spark.executorEnv.ARROW_LIBHDFS3_DIR="$PATH_TO_LIBHDFS3_DIR/"
--conf spark.executorEnv.LD_LIBRARY_PATH="$PATH_TO_LIBHDFS3_DEPENDENCIES_DIR"
--jars $PATH_TO_JAR/spark-arrow-datasource-standard--jar-with-dependencies.jar,$PATH_TO_JAR/spark-columnar-core--jar-with-dependencies.ja
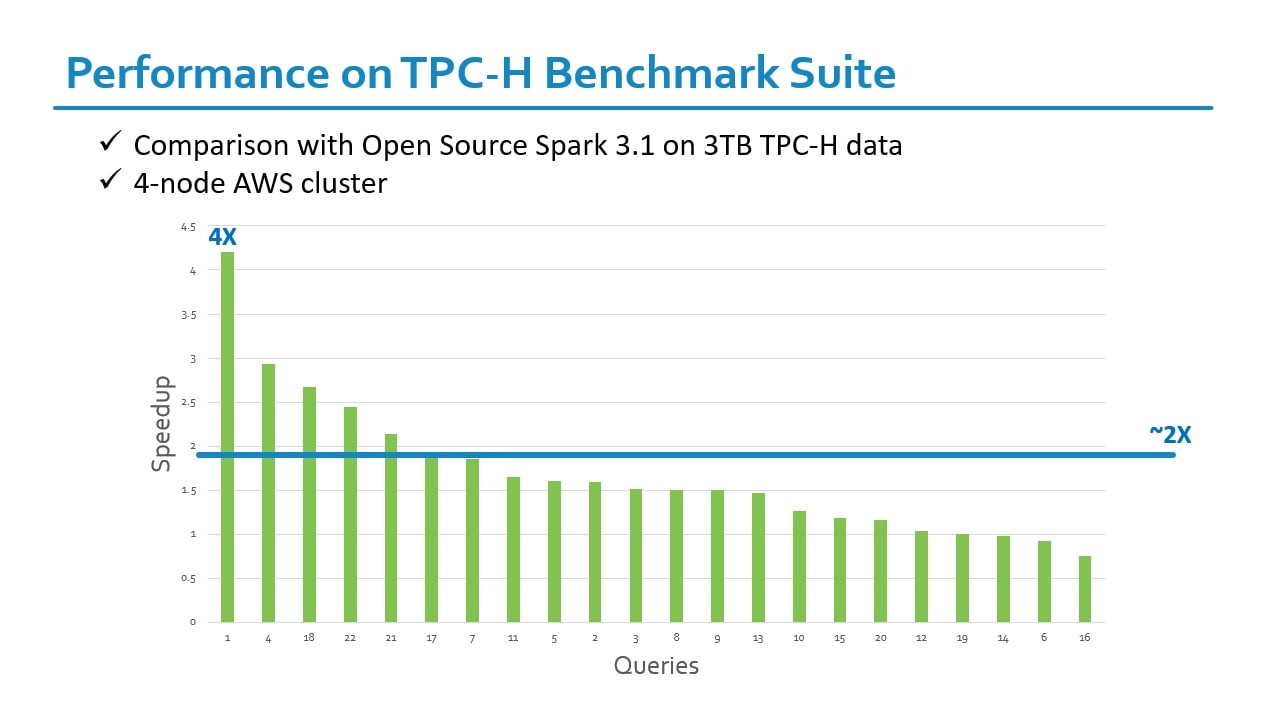
Performance on TPC-H Benchmark Suite
Setup Environment: 4-node AWS cluster, ensuring appropriate instance types, network configurations, and security settings. Install and configure Open Source Spark 3.1 on the cluster. Install and configure Intel OAP on the same cluster, ensuring compatibility with Spark 3.1.
Data Preparation: Loaded the TPC-H dataset, which simulates a decision support workload, into a distributed file system based on HDFS. We chose a dataset size of 3TB, which is the standard scale for TPC-H benchmarks
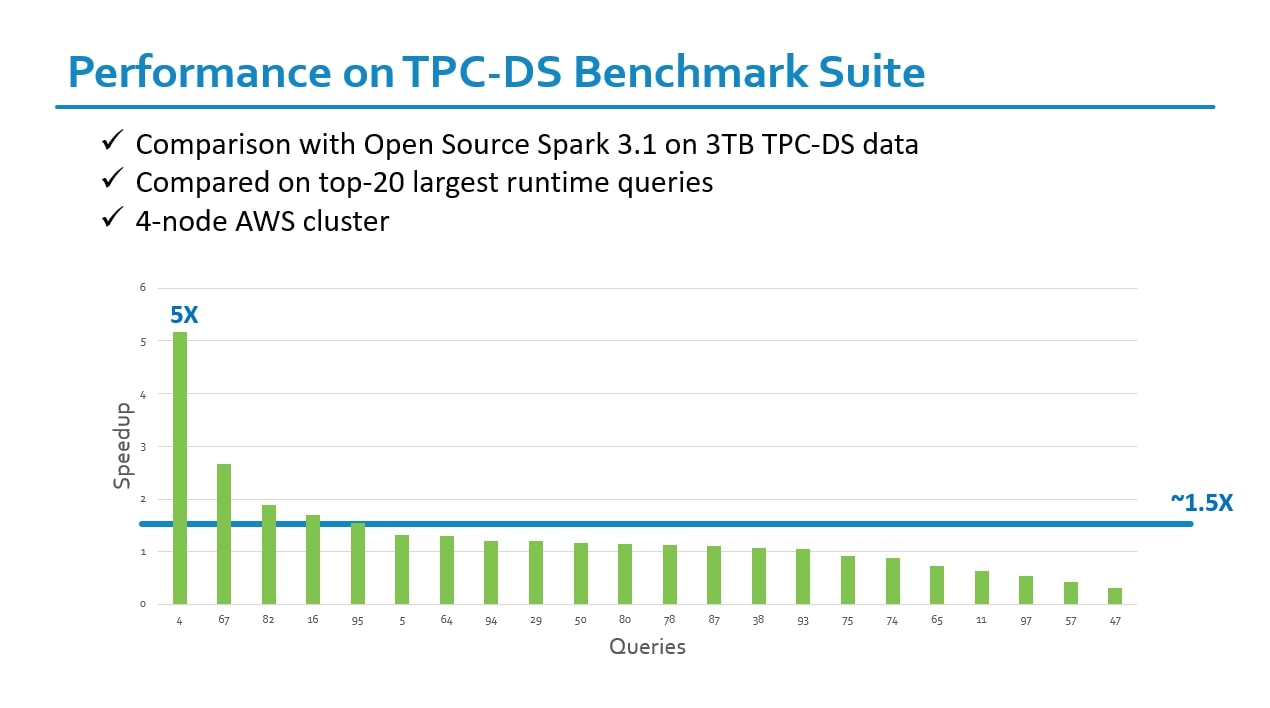
Performance on TPC-DS Benchmark Suite
Setup Environment: 4-node AWS cluster, ensuring appropriate instance types, network configurations, and security settings. Install and configure Open Source Spark 3.1 on the cluster. Install and configure Intel OAP on the same cluster, ensuring compatibility with Spark 3.1.
Data Preparation: Loaded the TPC-DS dataset, which simulates a decision support workload, into a distributed file system based on HDFS. We chose a dataset size of 3TB, which is the standard scale for TPC-DS benchmarks.
Conclusion
We saw significant improvements in Spark's performance by combining the power of Intel OAPs' Gazelle plug-in. Since the OAP setup does not require any change in compute resources, these speed-ups directly translate into 30-50% cost savings. Intel OAP shows the power of C++ based optimizations of SQL operations which can provide significant value beyond what default Open Source Spark can provide.
