Accelerating Fraud Detection Training Using GPUs

Introduction
Fraud detection is a critical task for various industries, such as finance, e-commerce, and insurance. To improve the accuracy and efficiency of fraud detection, we conducted an assessment on Graph Neural Networks (GNN) using Nvidia’s GP package versus standalone CPU flow using TigerGraph and DGL libraries. The assessment aimed to set up benchmark data, configure Nvidia and TigerGraph notebooks, run fraud detection on both platforms, compare the results, and analyse the data loader part of the Nvidia GP package.
Methodology
-
Benchmark Data Setup
To simulate real-world fraud detection scenarios, we used TabFormer as suggested by Nvidia's team.
Nvidia's Blog : Fraud Detection in Financial Services with Graph Neural Networks and NVIDIA GPUs | NVIDIA Technical Blog
Stats of TabFormer
- 24 million unique transactions
- 6000 unique cards
- 100,000 unique merchants
- 30,000 fraudulent samples (0.1% of total transactions)
-
Setting up Nvidia and TigerGraph Notebooks
To implement GNN-based fraud detection, we employed Python with the Nvidia GP package and GSQL with TigerGraph. The Nvidia GP package provides state-of-the-art tools for developing and training GNN models, while TigerGraph's GSQL is specifically designed for graph analytics and enables efficient graph processing.
-
Running Fraud Detection Notebooks on Cluster
Both the TigerGraph and Nvidia GP notebooks were deployed on a dedicated cluster to ensure a level playing field for evaluation. The cluster specifications were standardised to eliminate any hardware-related biases during the assessment 3.
Results: The fraud detection notebooks were executed on the benchmark dataset using the respective platforms. The results obtained are as follows:
Model Performance Mode Nodes GPU Model Accuracy Epochs Preprocessing Time (sec) Model Training Time (sec) CPU 1 0 0.9788 2 99.9 500 GPU 1 4 0.979 2 28.89 52.3 GPU 2 1 * 4 0.98 2 28.44 62 GPU 2 2 * 4 0.981 2 26.79 62.51
| Total Nodes | RAM | CPU | GPUs | Connection |
|---|---|---|---|---|
| 2 | 512G | 128 Core | 4 GPU * A100 40G | UCX |
Observation
- GPU Training Scalability: Training the GNN model on a single node with multiple GPUs demonstrated good scalability, as evidenced by the experiments using 4 GPUs single node.
- GPU vs. CPU Training Speed: The experiments consistently showed that GPU training is approximately 10 times faster than CPU training. This highlights the importance of utilizing GPUs for parallel processing, especially for computationally intensive tasks like training GNN models for fraud detection.
- Pre-processing Time: The pre-processing time for the experiments was relatively consistent across different configurations (single GPU and multiple GPUs). This suggests that the pre-processing steps are not well-optimized for parallelization and may be bottlenecked by a single GPU for certain parts of feature engineering and other preprocessing tasks.
- Lack of Improvement in 8-GPU Setup:
- When moving from a 4-GPU setup to an 8-GPU setup, there was no noticeable reduction in the model training time. This behavior suggests that the GP package used for GNN training might not be effectively distributing the training workload across multiple GPUs in the 8-GPU configuration.
- Further investigation and resolution from Nvidia's team are required to address this issue and optimize the multi-GPU training.
Next Steps
We are going to work on Data loader architecture and GP team Nvidia Team parallelly work on GP multi node issues.
Improve TG Data Loader Integration
As mentioned in the observation, the TG data loader integration needs further enhancement. Optimising the data loader can potentially improve the overall pre-processing time and contribute to better training efficiency. On proposal 1 as mentioned below.
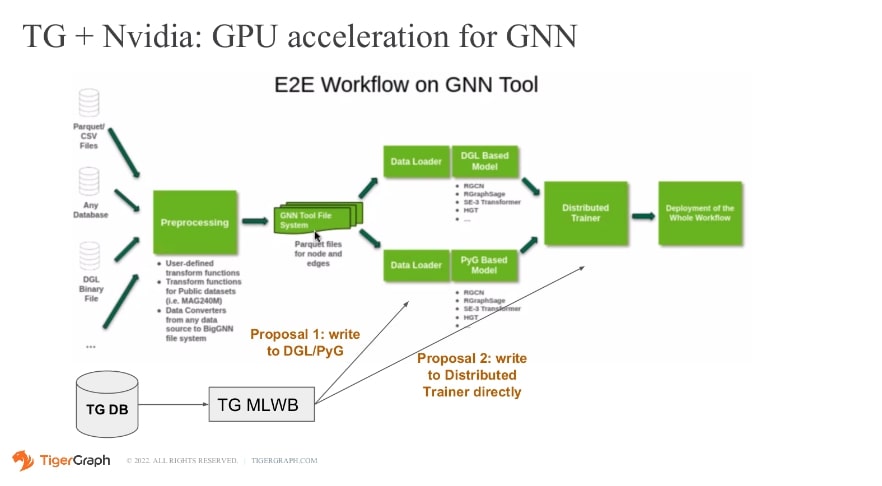
Conclusion
The assessment of GNN with data loading integration from TigerGraph for fraud detection provided valuable insights into the scalability and efficiency of the model training process. While GPU training demonstrated excellent scalability on a single node, there were challenges observed in multi-node setups and 8-GPU configurations. Addressing these issues and optimising the data loading process will likely lead to better performance and more efficient fraud detection systems.
