Turbocharge Fraud Detection Using Graph Analytics

Problem Overview
For a major credit card company, their training pipeline for Credit Card Fraud Detection would take months to finish. Detection of fraud was also taking seconds to complete. They were exploring Graph Analytics to speedup the entire process but were not meeting their SLAs. That’s when Zettabolt got involved. Our skilled experts evaluated various choices (scale up/out of CPUs, FPGA/GPU based acceleration etc.) and profiling the existing setup. We started with profiling first. We figured out that a rewrite of GSQL would provide some gain. On top of that, we had to provide custom UDFs for Page Rank algorithms. With these changes, training runtime improved by more than 100x and fraud detection runtime came to be within a second. Customer was thus able to meet the desired SLAs!
Customer Setup
The task at hand involves computing the Page Rank for all merchants engaged in transactions within a specific timeframe across a set of credit cards. For instance, over a six-month period with a dataset containing 100 million cards, we aim to calculate the Page Rank for all merchants involved in transactions during this duration.
Example Dataset
- Duration: 6 months
- Number of Cards: 100M
Possible Solutions
- Optimization of G-SQL according to TigerGraph's official documentation.
- Implementing scale-in/scale-out strategies.
- Exploring the utilization of custom hardware accelerators such as FPGA/GPU.
Though attempts have been made with solutions 1 and 2, achieving the desired performance remains elusive. For option 3, profiling is necessary to determine which aspects of the algorithm could be offloaded to hardware for optimization.
Profiling
Breaking down the problem into computational steps:
- Graph traversal runtime
- Involvement of I/O operations (Disks/Network) for large graphs
- CPU utilization for the core Page Rank algorithm
Evaluation for Hardware Accelerators: Prior to delving into hardware acceleration, several considerations need to be addressed, including data transfer, scaling with devices, concurrent execution, and partitioning of computational tasks.
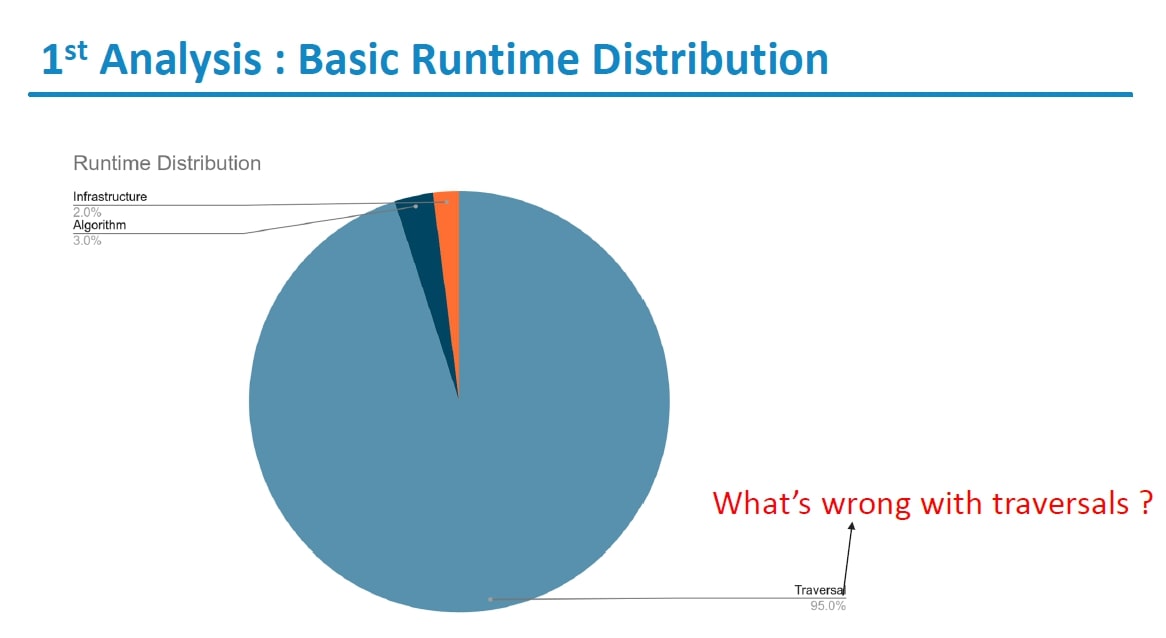
Software Model for H/W Accelerator
A software model is required to emulate the behavior of the hardware accelerator. This involves utilizing optimized graph operators and Zetta graph format for efficient data transfer.
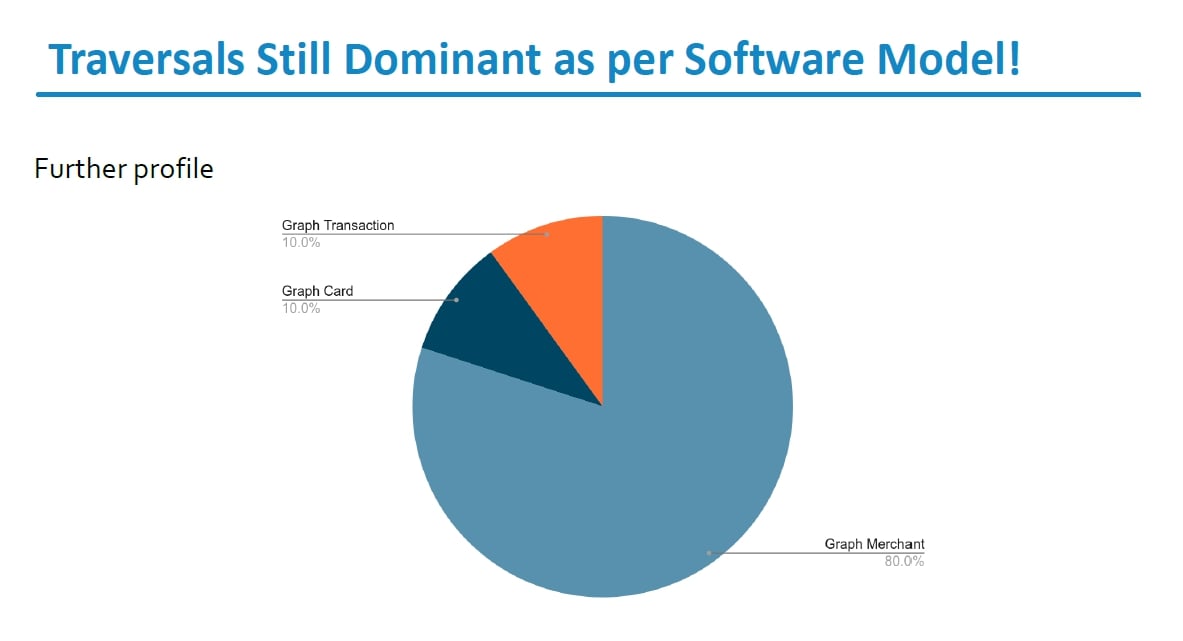
Solution to Slow Traversals
Caching the merchant graph, which is relatively small in size, helps expedite traversals. This cached data is stored in Zetta graph format across memory nodes.
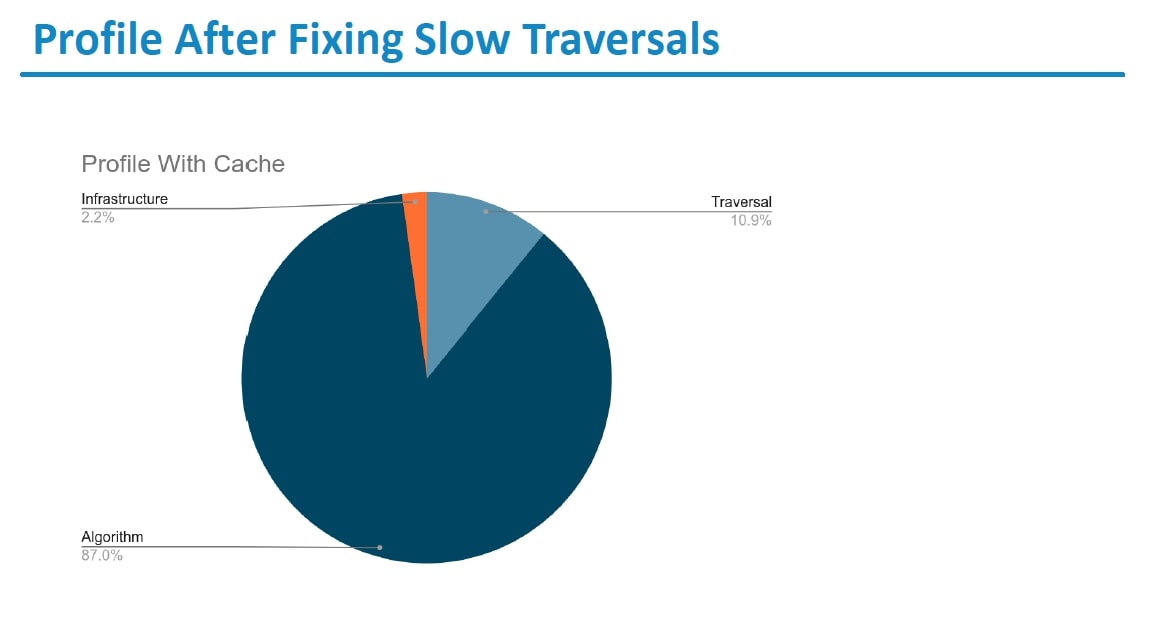
Training Runtime
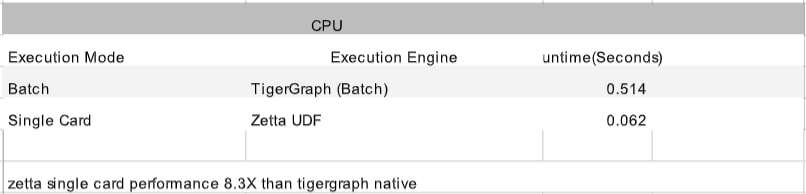
Batch processing of multiple credit cards is facilitated using C++ based UDF for Page Rank.
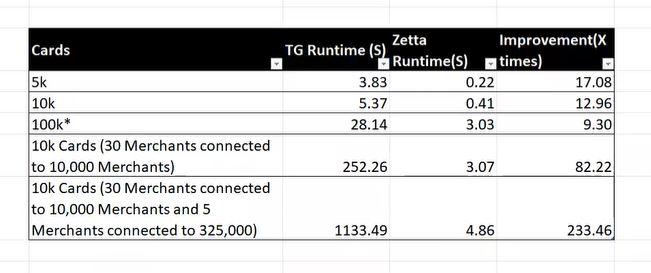
Inference Runtime
For single credit card Page Rank computation, Zetta runtimes with C++ based UDF are employed.
Summary
Efforts to enhance GQL performance at TigerGraph include thorough profiling, identifying bottlenecks, caching frequently accessed graphs, and designing UDFs to leverage caching for computation. If optimal performance is still not achieved, considering hardware accelerators such as FPGA or GPU becomes imperative.
