Architecture to Integrate TigerGraph with NVIDIA GNN

Table of Contents
- Introduction
- Scope of the Assessment
- Architecture Overview
- Strengths and Weaknesses
- Performance Evaluation
- Scope of work
1. Introduction
The purpose of this document is to assess the architecture of the integration between TigerGraph Data Loader and the NVIDIA GP package to determine its overall effectiveness, identify strengths and weaknesses, and provide recommendations for improvements.
2. Scope of the Assessment
The scope of this assessment is to comprehensively evaluate the architecture pertaining to the integration of TigerGraph Data Loader with the NVIDIA GP package and its impact on the performance, and maintainability of the system. The assessment encompasses the following key areas:
2.1 Integration Architecture
We will examine the architectural components and interactions involved in the integration of TigerGraph Data Loader with the NVIDIA GP package. This includes the role of data loader instances, the Kafka messaging system, and the data producer, with a focus on data distribution and communication.
2.2 Performance and Scalability Evaluation
The assessment will involve a performance evaluation, comparing the model training speed in two scenarios: first, with the standalone GP package and its default data loader, and second, with the integration of TigerGraph Data Loaders. Scalability will also be explored to determine how the system responds to increased resources.
3. Architecture Overview
3.1. Architecture 1: Using parquet file as input to GP package
In this architecture, data is accumulated from TigerGraph Data Loader batches, meticulously combined, processed, and then written back to the Parquet format, a traditional choice used by the GP package as the input for training Graph Neural Network (GNN) models.
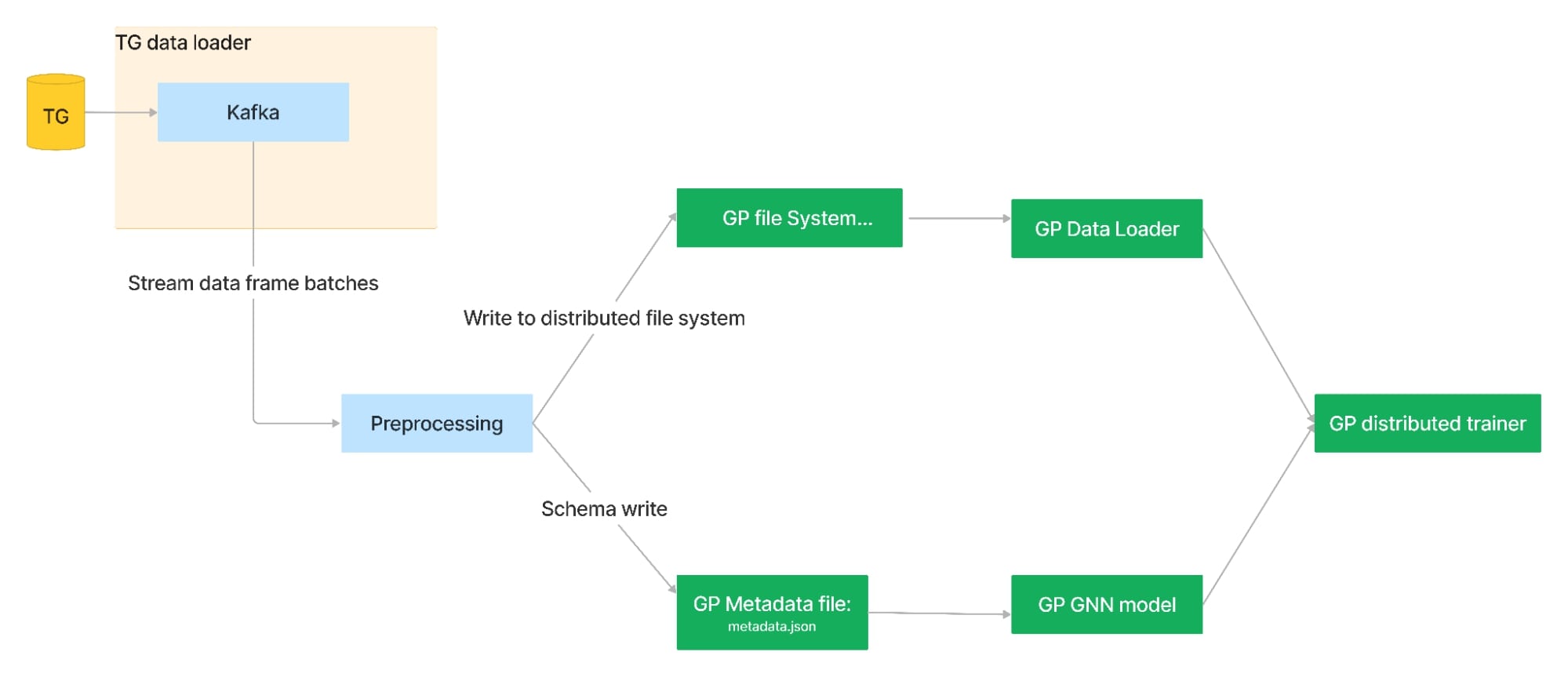
3.1.1 Architectural components and Data flow:
GP input file preparation
1. The batches of data obtained from the TigerGraph Data Loader are systematically collected and merged, resulting in the creation of a single extensive dataframe.
2. Subsequently, this unified dataframe undergoes a series of refinements to enhance its quality and usability. It is then methodically written to a Parquet file stored on the disk.
3. The path to this Parquet file is specified during the creation of the data loader within the GP package, facilitated through the utilisation of the metadata file. This enables the GP package to seamlessly access and utilise the preprocessed data for Graph Neural Network (GNN) model training.
GNN model training:
4. The parquet file data is used by GP to construct an in-memory graph.
5. Leveraging the constructed graph, batches of data are proficiently generated utilising well-established libraries such as PyG (PyTorch Geometric) or DGL (Deep Graph Library).
3.1.2 Strengths and Weaknesses:
Strengths
- Easy to design and implement
Weaknesses
- Disk write involve
- Dependency on Kafka
- Complete graph required in memory
- Scalability issue
Architecture 2: Using modified GP data loader
In this architecture the integration of TigerGraph Data Loader with the NVIDIA GP embodies a meticulously crafted system designed to optimise the loading and processing of data, specifically tailored for GNN model training. This architecture comprises several core components that synergize to facilitate an efficient data flow and are distinguished by their roles and interactions.
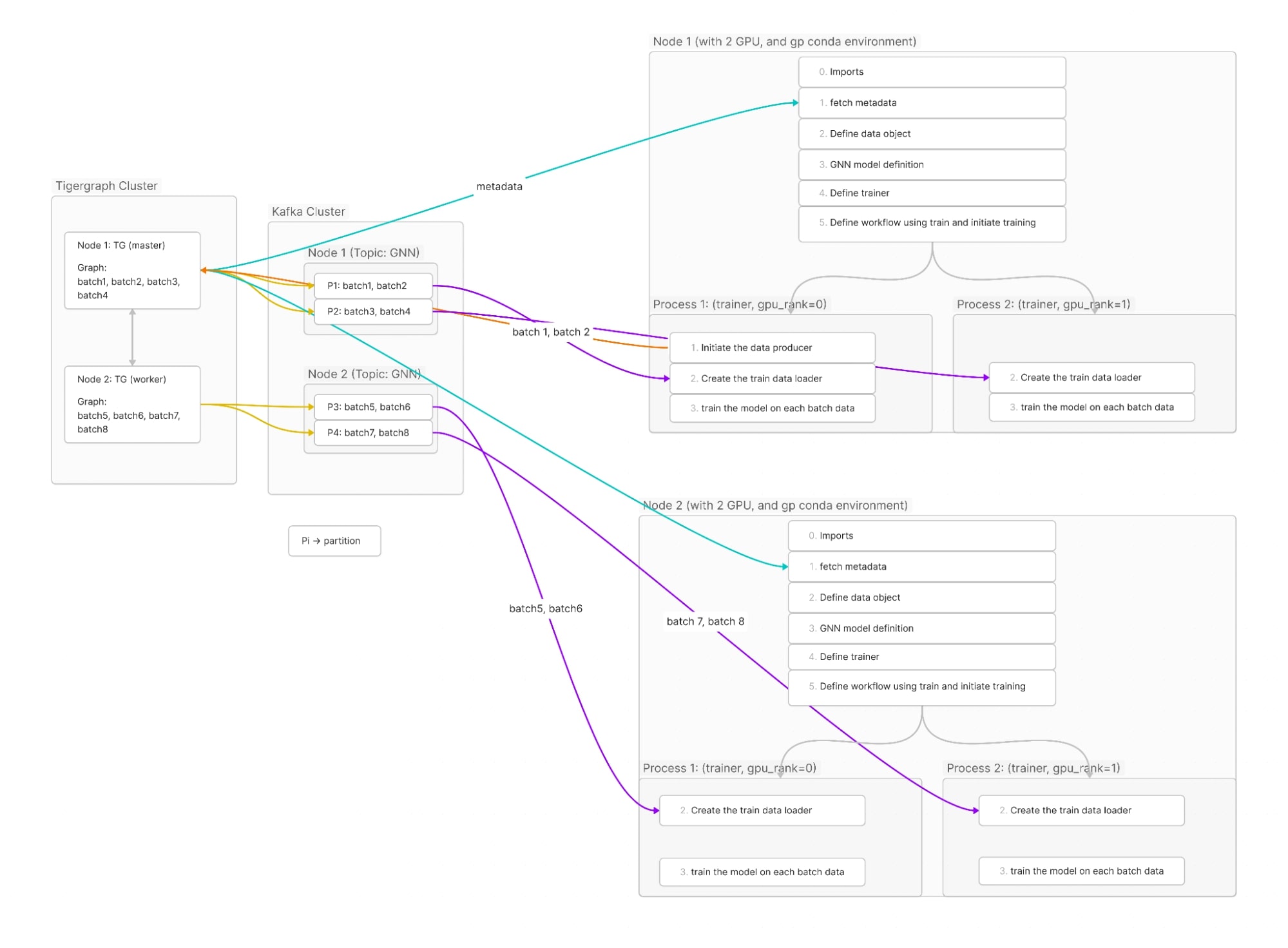
3.2.1 Components and Interaction
NVIDIA GP Package: At the foundation of this architecture lies the NVIDIA GP package, the nucleus of model training. The package orchestrates a dynamic number of worker instances, each entrusted with a distinct fragment of the training data. These worker instances collaboratively establish a distributed computing environment tailored for the pursuit of GNN model training excellence.
TigerGraph Data Loader: Complementing the GP package's endeavours is TigerGraph Data Loader, a versatile tool employed to instantiate data loader instances, each intricately aligned with a dedicated worker engendered by the NVIDIA GP package. These data loader instances serve as indispensable conduits for the efficient loading and processing of data, ensuring that the model training process unfolds with maximum efficiency.
Kafka Messaging System: To fortify the seamless transmission and dissemination of data, a Kafka messaging system is judiciously deployed. Kafka, renowned for its capabilities in high-throughput data streaming and distribution, is configured with an intricately defined topic and a Kafka consumer group to channel the data between producers and consumers( data loaders).
Data Producer: The data producer in this ecosystem is instrumental in meticulously populating data into a single, dedicated Kafka topic. This topic serves as the primary conduit for data distribution to consumers within the group. Notably, the data producer dynamically creates partitions within this single topic, ensuring that the number of partitions aligns precisely with the number of consumers in the group. This strategy guarantees an equitable and efficient distribution of data while optimising parallel processing during model training.
Data Loaders as Consumers: Each of the meticulously crafted data loaders, created and governed by TigerGraph Data Loader, is strategically positioned as a Kafka consumer. These data loader instances, thoughtfully designed to align with the workers spawned by the NVIDIA GP package, fulfil the crucial responsibility of consuming data from the Kafka topic partition correlated with their associated worker. The architectural symphony ensures a harmonious and balanced distribution of data to fuel the model training process.
3.2.2 End to end training process: An example
Let's train a link predictor model using this architecture on tab former dataset.
GP Prerequisites
Metadata file: The GP package should have access to a metadata file containing crucial details about the schema of the graph and data counts. This metadata file plays a central role in the design of the input layer for the Graph Neural Network (GNN) model and also useful in GNN model creation within the GP package.
TigerGraph Prerequisites
Data in TigerGraph Database: The TigerGraph database should be preloaded with your training, validation and test data. This dataset forms the foundation of our training process.
Kafka Service: The Kafka service should be up and running and accessible to TigerGraph. This ensures smooth communication and data distribution within the architecture.
Let's break down the steps involved in training our link predictor model:
Step 1: Create metadata file: metadata.json
The metadata file contains essential schema details related to graph data. It plays a pivotal role in the design of the input layer for Graph Neural Network (GNN) models within the GP package and is a foundational component when defining these GNN models.
Sample example for metadata.json
{
"nodes": {
"node_types": [
{"name": "card", "features": []},
{"name": "merchant", "features": []}]
},
"edges": {
"edge_types": [
{ "name": "transaction",
"src_node_type": "card",
"dst_node_type": "merchant",
"features": [
{"name": "year", "dtype": "int64", "shape": [24198836]},
{"name": "month", "dtype": "int64", "shape": [24198836]},
{"name": "day", "dtype": "int64", "shape": [24198836]}],
"generate_reverse_name": "transaction_rev"
}
]}}
To create the above, we use GSQL queries.
Step 2: Create your Data Loader
Before you embark on model training, you must create a data loader instance. This involves defining a TGLPDataObject and configuring it to your specific needs. This data object is responsible for managing the flow of data between the TigerGraph database and the GP package.
data_object = TGLPDataObject(
train_dataloader=train_spec,
valid_dataloader=val_spec,
test_dataloader=test_spec,
graph_name="tabformer",
v_in_feats = {"card": ["id"], "merchant": ["id"]},
e_in_feats = {"transaction": ["feat1"],},
backend="PyG",
tg_connection=conn,
n_gpus=4,
....
)
train_spec, val_spec, and test_spec contains the details like batch size, number of neighbours in sampling etc.
Step 3: Define your GNN Model
Next, you need to define your Graph Neural Network (GNN) model. For our scenario, let's consider a Relational Graph Convolutional Network (RGCN) model. The GP package provides a simple interface to create the RGCN model where you specify details such as the input layer, hidden dimensions, layers, and dropout rate to create your model. Then, you can establish your link predictor model, specifying the RGCN as encoder and DotProduct as decoder (again this link predictor model interface available in GP package).
encoder_model = RGCN(
input_layer=input_layer,
dim_hidden=64,
dim_out=64,
n_layers=2,
use_self_loop=True,
dropout=0.2
)
model = LinkPredictor(
encoder=encoder_model,
decoder=EdgeDotProductDecoder(),
targeted_etype=("card", "transaction", "merchant"),
)
Step 4: Create GP Trainer and Start Training
With your data loader and GNN model ready, it's time to initiate the training process. You create a GP Trainer, configuring it with the data object, model, optimizers, loss criterion, and other training parameters. The trainer is set up to run on multiple GPUs for enhanced performance. The Workflow wraps around the trainer, providing useful functionality, and then you initiate the training process using wrk.fit().
trainer = Trainer(
data_object=data_object,
model=model,
optimizers=optimizers,
criterion=torch.nn.BCELoss(),
n_gpus=4,
epochs=4,
metrics={"acc": BinaryAccuracy()},
amp_enabled=False,
output_dir=output_dir
)
# Workflow wraps the trainer and provides some useful functionality
wrk = Workflow(trainer=trainer)
wrk.fit()
For the reference, complete notebook available here
3.2.4 Scalability
At the heart of this architecture lies the tenet of scalability. The architecture effortlessly accommodates the evolving demands of the system. By adjusting the number of workers within the NVIDIA GP package and their corresponding data loader instances, the system seamlessly adapts to handle increasing workloads of graph data without compromising on efficiency.
3.2.5 Strengths and Weaknesses
Strengths:
- Direct TG data loader integration with GP package
- No In-Memory Full Graph Required
- No disk write involve
Weaknesses:
- Dependency on Kafka as an Additional Service
4. Comparison: Architecture 1 vs Architecture 2

5. Scope of work
5.1 Data object design [Zettabolt]
- The data object serves as a user interface for the creation of a distributed data loader.
- Beneath the surface, it orchestrates the creation of data loaders, each with the responsibility of efficiently providing data input in batches for the training of Graph Neural Network (GNN) models.
data_object = TGLPDataObject(
train_dataloader=train_spec,
valid_dataloader=val_spec,
test_dataloader=test_spec,
graph_name="tabformer",
v_in_feats = {"card": ["id"], "merchant": ["id"]},
e_in_feats = {"transaction": ["feat1"],},
backend="PyG",
n_gpus=4,
*tg_connection_args,
*kafka_args
....
)
- This data object is responsible for creating the data loaders. It will handle negative sampling and handling naming mismatch between TG and GP data objects.
- The data object gets associated with distributed trainers of GP and creates distinct instances of data loader for each trainer.
- TG data loaders need a flag which tells whether to initiate data producer or not which would be handled by master node only.
5.2 Automation of Metadata File Creation [Zettabolt, Tigergraph]
- Metadata file is required for model definition and input layer definition.
- It contain the details about graph node and edges details.
- This file creation can be simply automated using the help of GSQL queries.
5.3 Revisions to the GP Input Layer [Nvidia]
- The GP package node input layer requires a full graph and this graph is used to calculate node counts.
- This is a bottleneck for us as we are not loading the complete graph in memory.
- Though, this issue could be solved if we use the metadata file to take node count instead of the complete graph.
