Building a Private, Semiconductor-Aware RAG System
ZettaLens provides natural language access to internal Google Drive knowledge, powered by a locally hosted Llama 3.1 8B Instruct model for privacy, governance, and on-prem control.
Project Mission
Semiconductor engineering documentation spans specs, ECOs, bring-up logs, validation notes, and characterization data. ZettaLens provides citation-grounded, permission-aware, semiconductor-aware answers while keeping documents, embeddings, prompts, and inference inside the company network.
Overview
Semiconductor teams operate in a high-entropy documentation environment. This project delivers a private RAG system that converts that sprawl into a citation-grounded, access-controlled question-answering experience without sending data to a cloud LLM.
ZettaLens implements an on-prem RAG pipeline backed by a locally hosted Llama 3.1 8B Instruct model to meet data privacy and governance requirements. Operationally, it includes: a Google Drive folder-to-knowledge-base synchronization script with MD5 tracking, a web UI for knowledge base management, multi-document/multi-format ingestion, an API-driven auto-accuracy checker, and a scalable deployment pattern (multi-instance services behind NGINX load balancing).
- What modules are present in the CTN module?
- What does register dr_5 do?
- What are the steps in Fetch Queue?
Problem statement
The core problem is not the absence of information; it is the cost of locating trustworthy, scoped answers. A "correct" answer in chip development is conditional on context: stepping/revision, operating corner, temperature, workload assumptions, and the document's authority (errata vs characterization vs draft spec).
- Private-by-design: documents, embeddings, prompts, and inference remain inside the company network.
- Cited answers: every non-trivial claim is traceable to a specific document section or table.
- Scope correctness: answers explicitly state conditions (stepping/corner/temp/workload) when relevant.
- Access control: enforce Google Drive permissions so users only retrieve what they're allowed to see.
- Operational readiness: incremental updates, monitoring, evaluation, and scalable deployment.
The assistant behaves like a careful engineer: it cites sources, states assumptions, distinguishes draft from authoritative docs, and says "insufficient evidence" instead of inventing limits. Retrieval quality is the product; generation is the summarizer.
High-level architecture
The platform is built around four subsystems:(a) ingestion and parsing,(b) indexing,(c) retriveal and answering, and (d) goverance/operations. The system treats retriveal quality as the primary product; generation is a structured summarizer over retrieved evidence

Figure 1. End-to-end architecture: ingestion → indexing → retrieval → glossary steering → local LLM → cited answers.
Data ingestion and parsing
Google Drive behaves like a living knowledge lake. The ingestion strategy focuses on incremental updates, reproducible indexing, and permission-aware retrieval.
Drive folder → Knowledge Base synchronization
To support multiple dynamic documents and concurrent usage, ZettaLens includes a Python synchronization script that mirrors a specified Google Drive folder into a specified knowledge base. The script maintains a registry of files and their MD5 checksums; newly added or changed files are downloaded, passed to the ZettaLens ingestion API, and indexed into the target knowledge base. The sync can be run on demand or scheduled at a fixed interval.
Multi-document and multi-format handling
The knowledge base pipeline supports multi-document updates and broad format coverage.
ZettaLens has been validated to ingest and index DOCX, TXT, PDF, HTML, CSV, and XLSX sources, and the knowledge base UI supports add/remove operations to manage evolving corpora.
Structure-aware parsing
Semiconductor documents are table-heavy. The parser preserves tables as structured artifacts where possible, so limits stay tied to conditions (corner, temp, stepping, test mode) instead of being shredded into unrelated text chunks.
Product surface: ZettaLens web UI
The web UI makes the system usable by engineers: authentication, knowledge base management, chat-based Q&A, feedback capture, and result visualization. The UI is intentionally simple: the goal is to reduce friction between "I have a question" and "I have cited evidence."
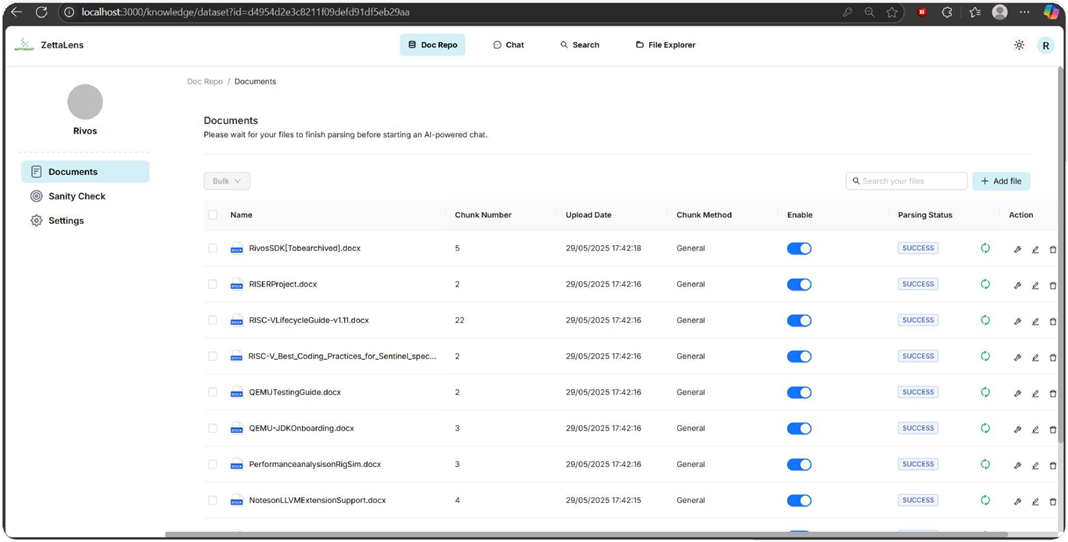
Figure 2. Login screen (ZettaLens UI).

Figure 3. Knowledge base document repository with parsing status and controls.
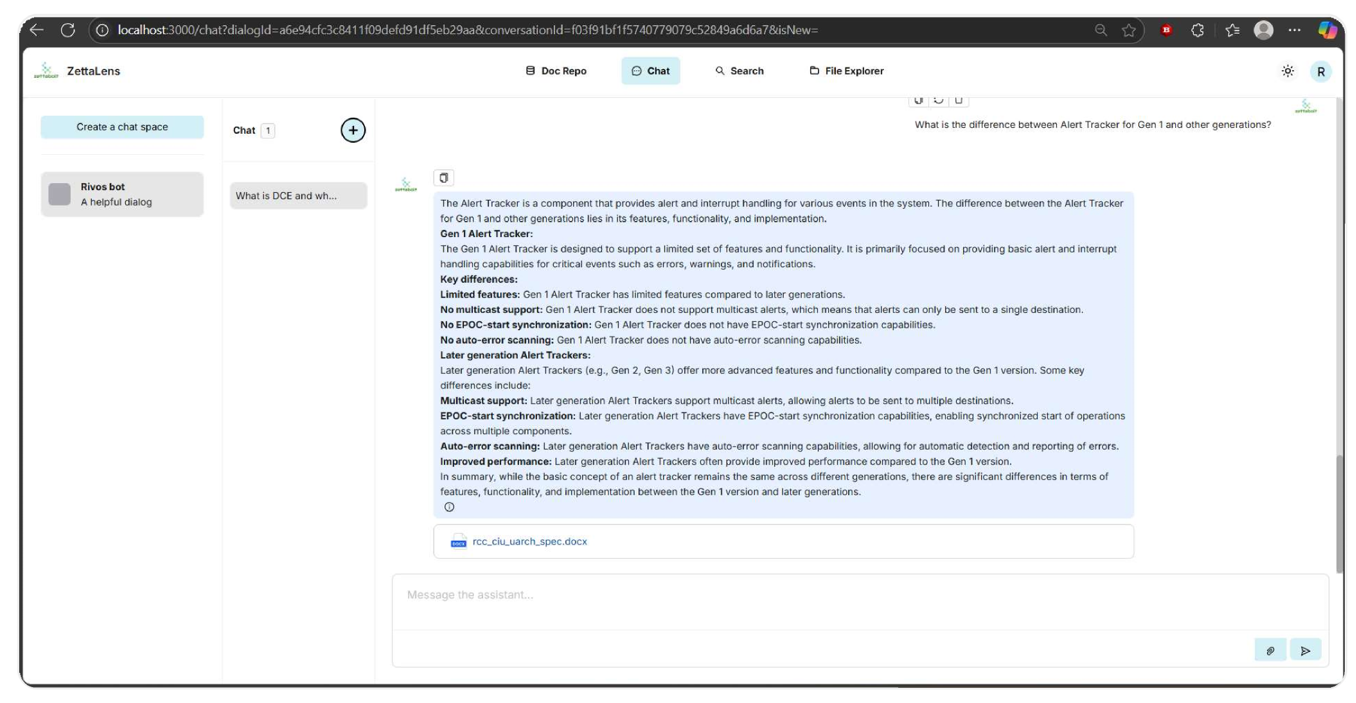
Figure 4. Chat experience with attached citations.

Figure 5. API-driven evaluation output: per-query response time and semantic similarity scores.
Retrieval strategy for semiconductor knowledge
Semiconductor corpora are acronym-dense and entity-heavy (register names, IP blocks, stepping labels, test modes). Pure vector retrieval can miss exact identifiers; pure lexical retrieval can miss semantic intent. A hybrid approach combines vector similarity with keyword/BM25 style retrieval, merges candidates, and applies reranking based on semantic relevance and metadata (doc type, authority, revision, and scope).
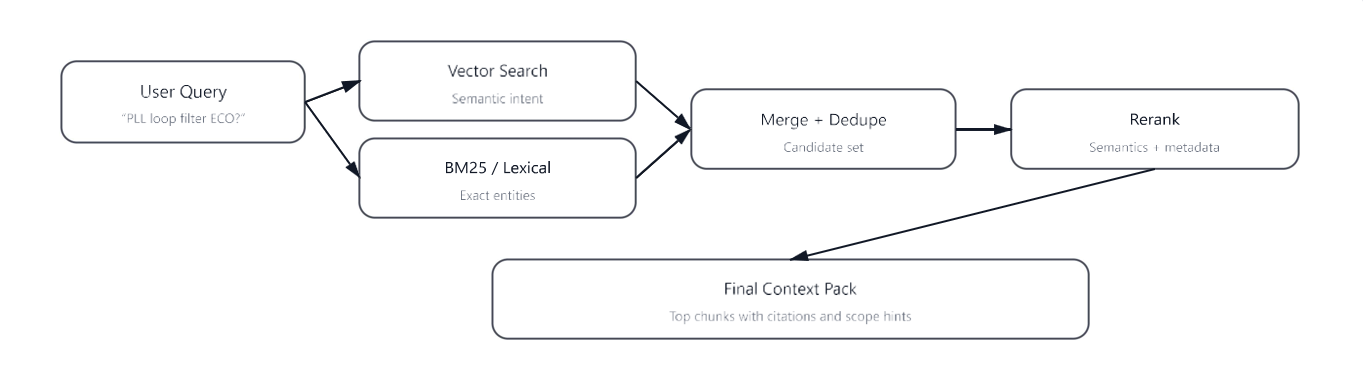
Figure 6. Hybrid retrieval: vector + lexical → merge/dedupe → rerank.
Glossary steering: making answers semiconductor-aware
The single biggest relevance lever is domain grounding. A curated glossary is used as an active component of the pipeline: it disambiguates overloaded terms (e.g., Vmin, corner, training), expands internal aliases and synonyms, and injects retrieval hints so the model sees the right context before generating an answer.
Recommended glossary entry fields
- Term and definition (engineering-precise, not generic).
- Aliases and internal synonyms (acronyms, code names, register nicknames).
- Allowed/typical contexts (which IP blocks, which lifecycle stages, which teams).
- Common confusions (what the term is not in your org).
- Retrieval hints (preferred doc types, tags, sections, tables).
{
"term": "Vmin",
"definition": "Minimum supply voltage meeting functional + timing requirements under specified conditions.",
"units": ["mV"],
"contexts": ["DVFS", "AVFS", "SRAM margin", "IR drop"],
"confusions": ["Not IO Vmin", "Not retention Vmin"],
"aliases": ["SOC_VMIN_TARGET", "SV_VMIN"],
"related": ["SS corner", "cold temp", "droop", "guardband"],
"retrieval_hints": {
"boost_doc_types": ["characterization", "silicon_validation"],
"prefer_sections": ["limits", "conditions", "tables"],
"boost_tags": ["stepping", "corner"]
}
}Testing and evaluation
ZettaLens includes an API-based auto-accuracy checking script to enable end-to-end testing of retrieval accuracy, metadata handling, and performance. The evaluation harness also supports benchmarking across different LLMs and embedding models.
In practice, this allows teams to track: (a) response latency, (b) semantic similarity between expected and generated answers, (c) retrieval hit-rate for authoritative documents, and (d) regression detection after pipeline changes.
What to instrument
- P50/P95 latency per stage: rewrite, retrieve, rerank, generate
- Recall@K / nDCG@K on a curated "golden" evaluation set
- Groundedness checks: does every key claim have a citation?
- Freshness distribution: time since last indexed revision
Model stack selection
Based on testing on the provided documents, the following configuration offered the best tradeoff between resource use and answer quality:
- LLM: Llama 3.1 8B Instruct (local)
- Embedder: sentence-transformers/all-MiniLM-L12-v2
- Reranker: cross-encoder/ms-marco-MiniLM-L-6-v2
Deployment on local servers
To support multiple engineers concurrently, the recommended deployment pattern runs multiple instances of the LLM, reranker, and embedder, fronted by NGINX for load balancing. This isolates heavy inference workloads, improves tail latency, and enables incremental horizontal scaling.
In the local deployment, the LLM service was hosted using vLLM. A single shared NVIDIA A100 GPU supported 10 concurrent users under interactive workloads.
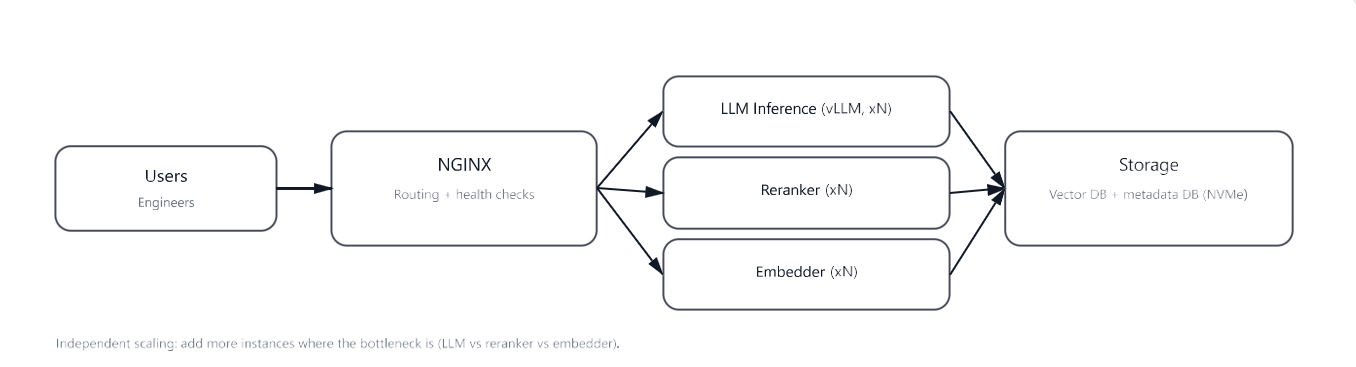
Figure 7. Deployment pattern: multiple inference services behind NGINX load balancing.
Deployment recommendations
- Separate services: run LLM inference, embedding, and reranking as independent processes; containers scale independently.
- Use NGINX: a simple, auditable load balancer for multi-instance routing and health checks.
- Prioritize NVMe: for vector index storage and parsing scratch space; avoid networked filesystems for hot indexes when possible.
- Instrument P50/P95: across stages (rewrite, retrieve, rerank, generate) and alert on regressions.
- Version everything: model builds, prompts, and glossary releases so answer behavior is reproducible.
What's next
Once a private RAG system is working, the next frontier is reliability at scale: better evaluation sets, stronger permission-aware ranking, and more helpful workflows (tickets, summaries, "show me the table", etc.).
Figure 8. Roadmap sketch: scaling, user management, agentic retrieval, and full RAG evaluation.
